大数据开发工程师-第四周 第三章 HDFS高级
HDFS的回收站
1 | HDFS也有回收站。 |
1 | <property> |

1 | 第二个一般不配置,默认就是第二条(值=0=第一条配置的value),如果要配置要符合第三条 |



1 | window要直接删除不经过垃圾桶:shift+delete |
1 | 修改回收站配置,先在bigdata01上操作,然后再同步到其它两个节点,先停止集群 |
1 | 回收站的文件也是可以下载到本地的。其实在这回收站只是一个具备了特殊含义的HDFS目录。 |
HDFS的安全模式
1 | 大家在平时操作HDFS的时候,有时候可能会遇到这个问题,特别是刚启动集群的时候去上传或者删除文件,会发现报错,提示NameNode处于safe mode。 |
1 | [root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r /hadoop-3.2.0.tar.gz |
1 | 此时访问HDFS的web ui界面,可以看到下面信息,on表示处于安全模式,off表示安全模式已结束 |
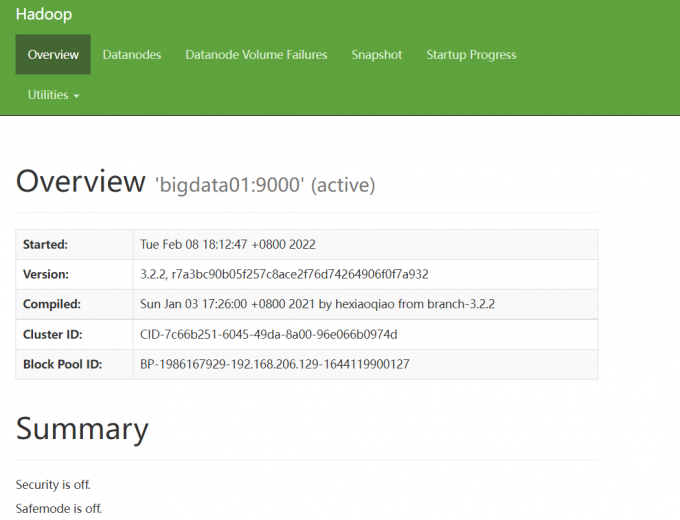
1 | 或者通过hdfs命令也可以查看当前的状态 |
实战:定时上传数据至HDFS
需求分析: 在实际工作中会有定时上传数据到HDFS的需求,我们有一个web项目每天都会产生日志文件,日志文件的格式为access_2020_01_01.log这种格式的,每天产生一个,我们需要每天凌晨将昨天生成的日志文件上传至HDFS上,按天分目录存储,HDFS上的目录格式为20200101
1 | 针对这个需求,我们需要开发一个shell脚本,方便定时调度执行 |
1 | [root@bigdata01 shell]# vi uploadLogData.sh |
1 | 生成测试数据,注意,文件名称中的日期根据昨天的日期命名 |
1 | 注意:如果想要指定日期上传数据,可以通过在脚本后面传递参数实现 |
1 | 这样后期如果遇到某天的数据漏传了,或者需要重新上传,就可以通过手工指定日期实现上传操作,在实际工作中这种操作是不可避免的,所以我们在开发脚本的时候就直接考虑好补数据的情况,别等需要用的时候了再去增加这个功能。 |
HDFS的高可用和高扩展
hadoop理论课-第三章HDFSHDFS高可用
1 | 针对目前这个一主两从的集群 |
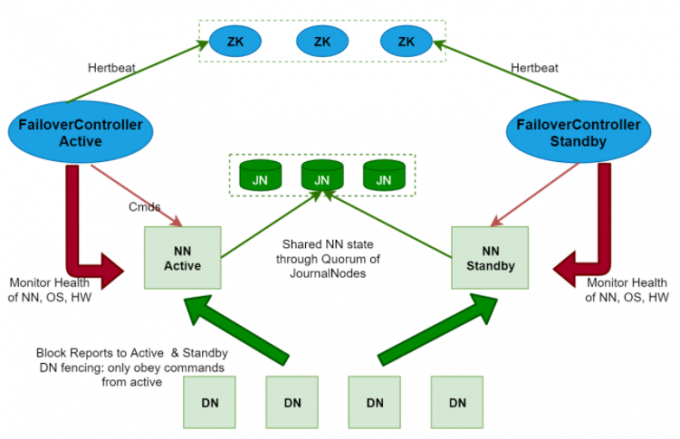
1 | 下面我们首先来看一下HDFS的高可用,也可以称之为HA(High Available) |
1 | 需要注意一点,为了保证Active NN与Standby NN节点状态同步,即元数据保持一致 |
1 | 注意:使用HA的时候,不能启动SecondaryNameNode,会出错。 之前是SecondaryNameNode负责合并edits到fsimage文件 那么现在这个工作被standby NN负责了。 |
配置HDFS 的HA
1 | 实际使用的CDH和HDP已经包含这个了,这一部分不做过多要求 |
1 | HA集群规划 |
1 | 解释:针对HDFS的HA集群,在这里我们只需要启动HDFS相关的进程即可,YARN相关的进程可以不启动,它们两个的进程本来就是相互独立的。 |
环境准备:三个节点
1 | bigdata01 192.168.182.100 |
1 | 每个节点的基础环境都要先配置好,先把ip、hostname、firewalld、ssh免密码登录、host、免密码登录,JDK这些基础环境配置好 |
1 | 但是注意:有一点还需要完善一下,由于namenode在进行故障切换的时候,需要在两个namenode节点之间互相使用ssh进行连接,所以需要实现这两个namenode之间的互相免密码登录,目前我们只实现了bigdata01免密码登录到bigdata02,所以还需要实现bigdata02免密码登录到bigdata01,这一步如果不做,后期无法实现namenode故障自动转移。 |
1 | 接着把bigdata01 、bigdata02 、bigdata03中之前安装的hadoop 删掉,删除解压的目录,以及hadoop_repo目录。 |
1 | [root@bigdata01 ~]# rm -rf /data/soft/hadoop-3.2.0 |
zookeeper
1 | 我们在这里需要使用到zookeeper这个组件,所以先把它安装起来。 |
1 | 2. 首先在bigdata01节点上配置zookeeper |
1 | 修改配置 |
1 | 创建目录保存myid文件,并且向myid文件中写入内容 |
1 | 3. 把修改好配置的zookeeper拷贝到其它两个节点 |
1 | 5. 启动zookeeper集群 |
1 | 6. 验证 |
1 | [root@bigdata01 apache-zookeeper-3.5.8-bin]# bin/zkServer.sh status |
1 | [root@bigdata02 apache-zookeeper-3.5.8-bin]# bin/zkServer.sh status |
1 | [root@bigdata03 apache-zookeeper-3.5.8-bin]# bin/zkServer.sh status |
1 | 7. 停止zookeeper集群 |
接下来我们来配置Hadoop集群
1 | 先在bigdata01节点上进行配置 |
1 | 修改core-site.xml文件 |
1 | 修改hdfs-site.xml文件 |
1 | mapred-site.xml和yarn-site.xml在这暂时就不修改了,因为我们只需要启动hdfs相关的服务。 |
1 | 修改启动脚本 |
1 | start-yarn.sh,stop-yarn.sh 这两个脚本暂时也不需要修改了,因为不启动YARN相关的进程用不到。 |
1 | 4. 格式化HDFS【此步骤只需要在第一次配置HA集群的时候操作一次即可】 |
1 | 接下来就可以对HDFS进行格式化了,此时在哪个namenode节点上操作都可以(bigdata01或者bigdata02),在这我们使用bigdata01 |
1 | 然后启动此namenode进程 |
1 | 5. 格式化zookeeper节点【此步骤只需要在第一次配置HA集群的时候操作一次即可】 |
1 | 6. 启动HDFS的HA集群 |
1 | 7. 验证HA集群 |

1 | 此时我们来手工停掉active状态的namenode,模拟namenode宕机的情况,验证一下另一个standby的 |
1 | 此时再刷新查看bigdata02的信息,会发现它的状态变为了active |

1 | 接着我们再把bigdata01中的namenode启动起来,会发现它的状态变为了standby |
1 | 通过前面的操作可以发现,现在的namenode其实就解决了单点故障的问题,实现了高可用。 |
1 | 8. 停止HDFS的HA集群 |
1 | 注意:大家在做完HA之后,再根据伪分布或者分布式集群的操作步骤重新操作一遍,因为后期的 |
HDFS高扩展
1 | 还有一个问题是,前面我们说了NameNode节点的内存是有限的,只能存储有限的文件个数,那使用一个主NameNode,多个备用的NameNode能解决这个问题吗? |
1 | HDFS Federation可以解决单一命名空间存在的问题,使用多个NameNode,每个NameNode负责一个命令空间 |
HA+Federation
1 | 如果真用到了Federation,一般也会和前面我们讲的HA结合起来使用,来看这个图 |
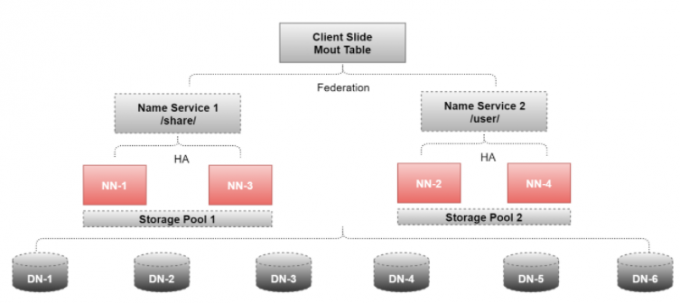
1 | 这里面用到了4个NameNode和6个DataNode |
1 | 注意:由于Federation+HA需要的机器比较多,大家本地的机器开不了那么多虚拟机,所以暂时在这就不再提供对应的安装步骤了,大家主要能理解它的原理就可以了,在工作中也不需要我们去配置。 |
快照
第三章 shell命令操作HDFS-常用HDFS管理命令 文章标题(可选)1 | linux系统也有快照功能 |



1 | hdfs dfsadmin 是和权限相关的 |








1 | 快照恢复用cp不能像回收机制那样用mv,因为只能读 |
配额
文章标题(可选) 文章标题(可选)归档
文章标题(可选)HDFS优缺点(面试)




优点
高容错




高吞吐量

高可靠

1 | 多副本:使用多个副本存储正常使用的文件 |
缺点
高时延

小文件问题


1 | 只支持增加文件内容 |
使用场景


