第五周 第一章 初识MapReduce
Hadoop之MapReduce详解
前面我们学习了Hadoop中的HDFS,HDFS主要是负责存储海量数据的,如果只是把数据存储起来,除了浪费磁盘空间,是没有任何意义的,我们把数据存储起来之后是希望能从这些海量数据中分析出来一些有价值的内容,这个时候就需要有一个比较厉害的计算框架,来快速计算这一批海量数据,所以MapReduce应运而生了,那MapReduce是如何实现对海量的快速计算的呢?它的底层原理是什么样的呢?不要着急,且听下面分解。
MapReduce介绍
1 | 在这里我们先举个例子来介绍一下MapReduce |
分布式计算介绍
移动数据计算(传统计算)
1 | 再举一个例子,就拿我们平时使用比较多的JDBC代码执行的流程来说。 |
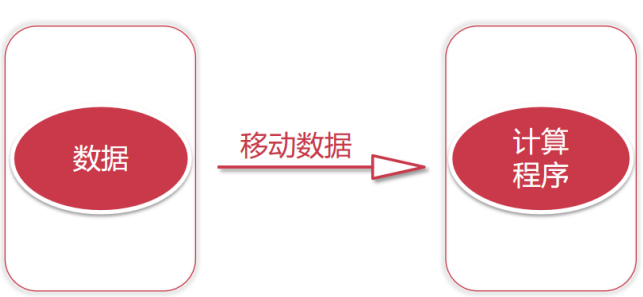
1 | 如果我们考虑把计算程序移动到mysql上面去执行,是不是就可以节省网络io了,是的! |
移动计算程序计算(新思路)
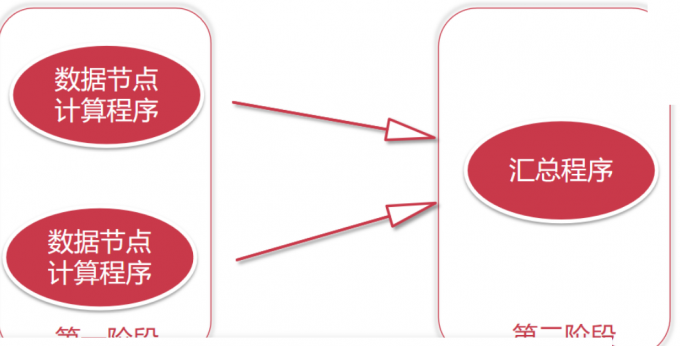
1 | 如果我们数据量很大的话,我们的数据肯定是由很多个节点存储的,这个时候我们就可以把我们的程序代码拷贝到对应的节点上面去执行,程序代码都是很小的,一般也就几十KB或者几百KB,加上外部依赖 包,最大也就几兆 ,甚至几十兆,但是我们需要计算的数据动辄都是几十G、几百G,他们两个之间的差距不是一星半点啊 |

1 | 这个计算过程就是分布式计算,这个步骤分为两步: |
MapReduce原理剖析
1 | MapReduce是一种分布式计算模型,是Google提出来的,主要用于搜索领域,解决海量数据的计算问题. |
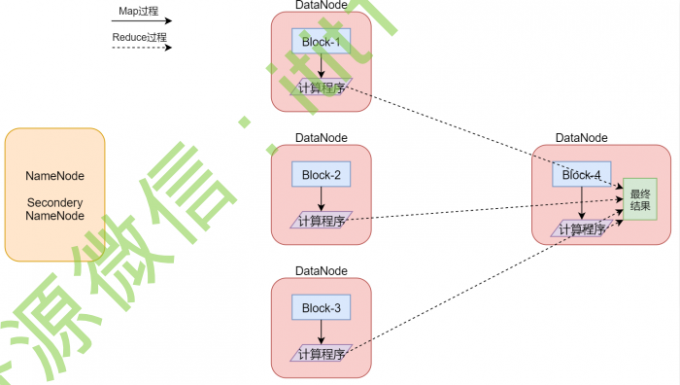
1 | 这是一个Hadoop集群,一共5个节点一个主节点,四个从节点 |
1 | 左下角是一个文件,文件最下面是几个block块,说明这个文件被切分成了这几个block块,文件上面是一些split,注意,咱们前面说的每个block产生一个map任务,其实这是不严谨的,其实严谨一点来说的话应该是一个split产生一个map任务。 |
MapReduce之Map阶段(六步)
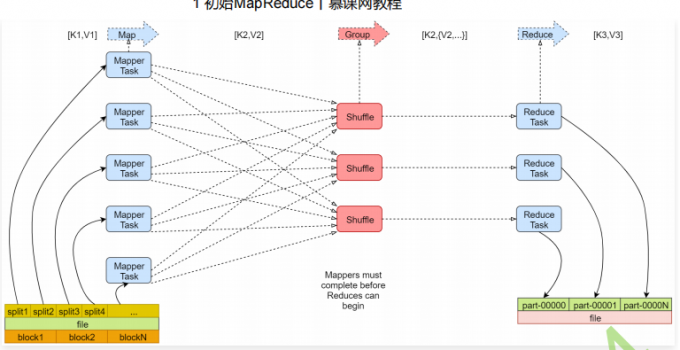
1 | mapreduce主要分为两大步骤 map和reduce,map和reduce在代码层面对应的就是两个类,map对应的是mapper类,reduce对应的是reducer类,下面我们就来根据一个案例具体分析一下这两个步骤 |
MapReduce之Reduce阶段(十步)
1 | 第一步:框架对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。这个过程称作shuffle |
wordcount实例简略过程
1 | map阶段: |
:

