第三章HDFS
HDFS简介
HDFS是Google公司的GFS分布式文件系统的开源实现
HDFS是Apache Hadoop项目的一个子项目
支持海量数据存储,成百上千的计算机组成存储集群
HDFS可以在低成本的硬件之上,具有高容错,高可靠性,高扩展,高吞吐率等特征
非常适合大规模数据集的应用
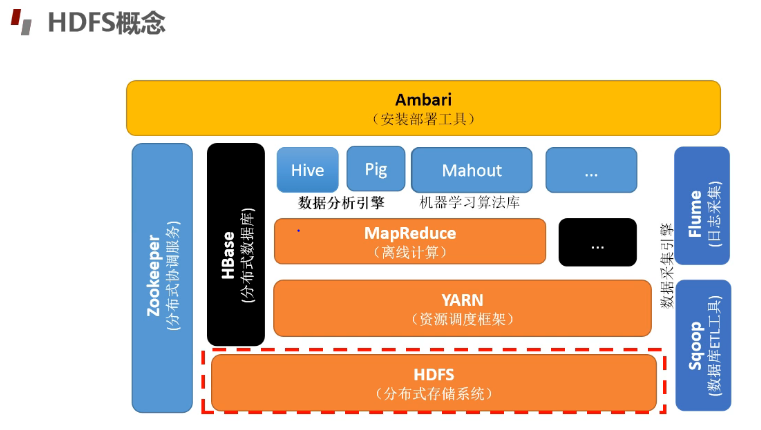
HDFS的生态圈
HDFS优点
高容错性
数据自动保存多个副本
副本丢失后,自动恢复
适合批处理
移动计算而非移动数据
移动位置暴露给计算框架
适合大数据处理
GB, TB, 甚至PB级数据
百万规模以上的文件数量
10k+节点
支持流式文件访问
一次写入,多次读取
保证数据一致性
可构建在廉价机器上
通过多副本提高可靠性
提供容错和恢复机制
HDFS缺点
不适合低延迟数据访问
比如毫秒级
低延迟与高吞吐率
不适合小文件存取
占用NameNode大量内存
寻找时间超过读取时间
不适合并发写入,文件随机修改
一个文件只能有一个写入者
仅支持append(附加)
HDFS的组成与架构
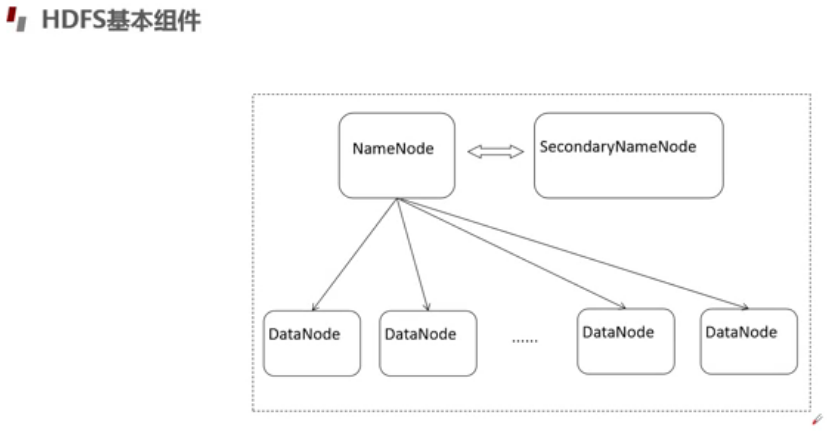
HDFS基本组件
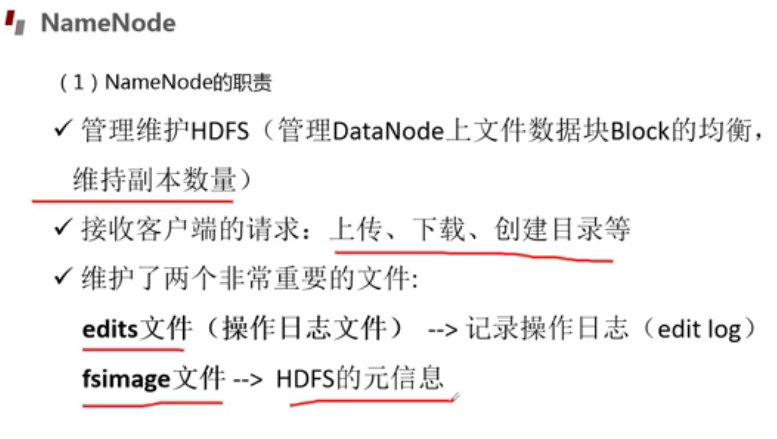
NameNode
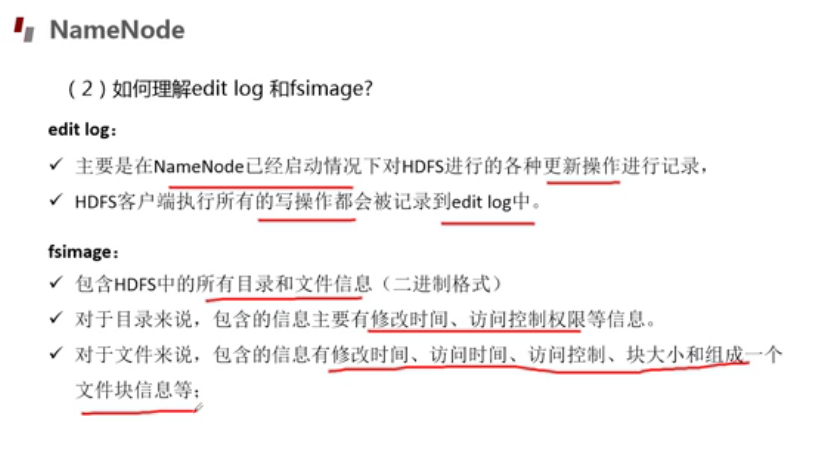
edits是日志文件,包含一条条edit log; fsimage是最终结果
DataNode
数据块

分块原因
- 一个巨大文件一块磁盘空间不够
- 利于备份
- 提高吞吐量(并发读写,计算,利用不同节点存储,减少一个节点的负载)
DataNode的主要职责
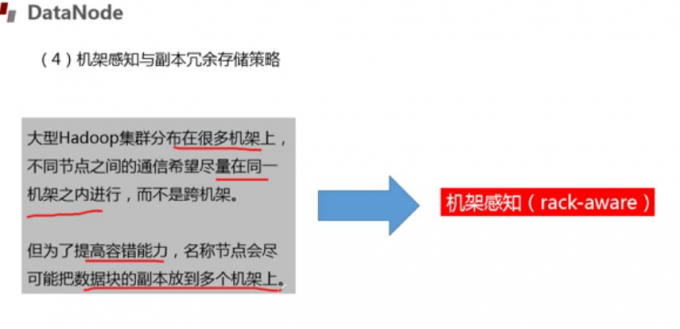
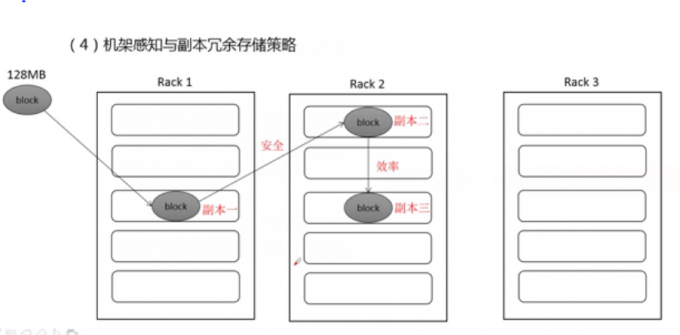
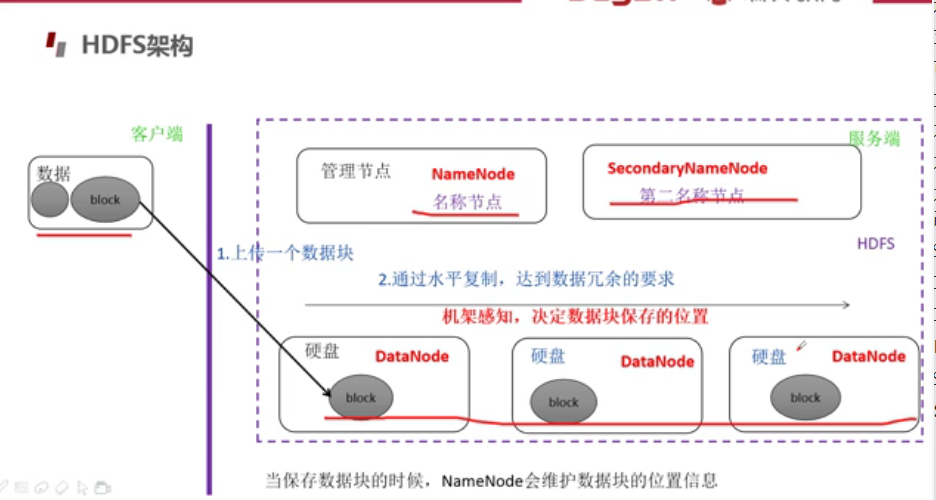
机架感知与副本冗余存储策略
Secondary NameNode
Secondary NameNode的职责
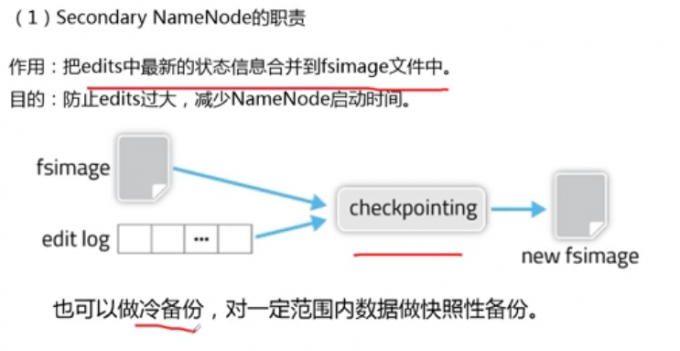
secondary namenode和namenode占用同样大的内存大小;在不同节点上
Secondary NameNode工作流程
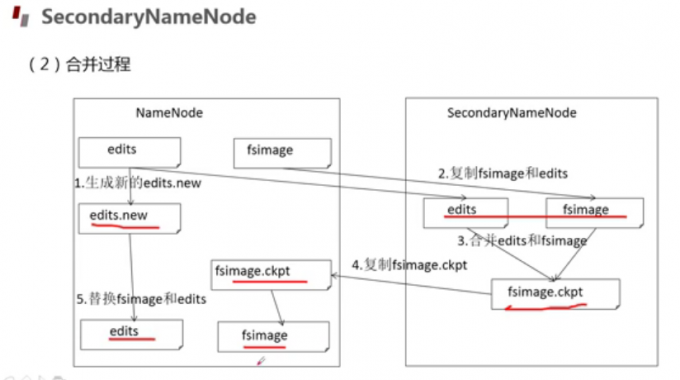
检查点
.htm/C:%5CUsers%5CTy%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20200402153039014.png)
问题

答案:edits。因为现在的fsimage保存的是最新也就是最近检查节点产生的fsimage;而现在的edits文件是保存的最近检查节点产生fsimage以来,Hdfs的操作信息
HDFS架构
操作HDFS
HDFS web访问
IP:50070访问NameNode
IP:50090访问SecondaryNameNode
HDFS shell访问
操作命令
管理命令
其它命令

Hadoop中三种shell命令

JAVA API端口访问

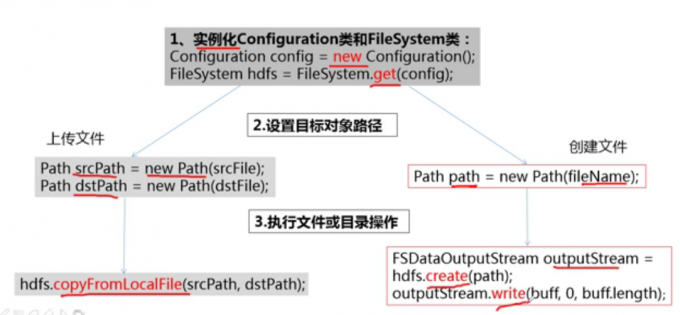
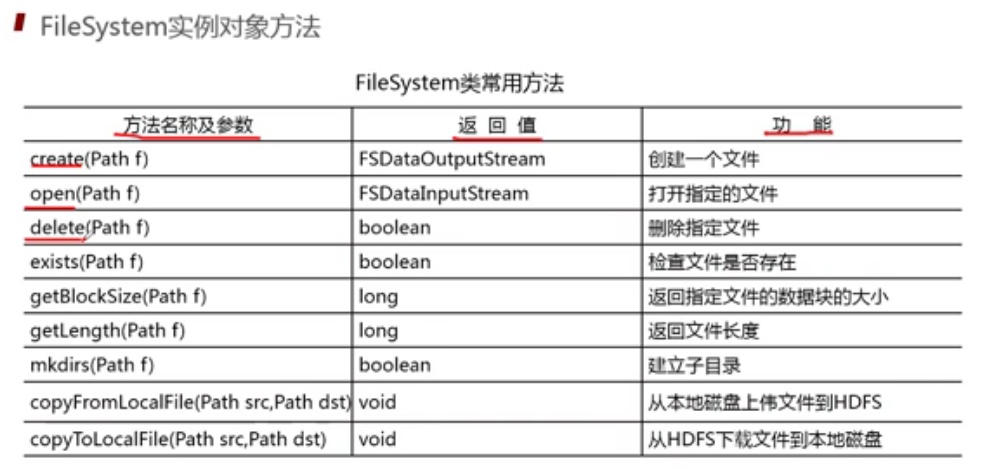
HDFS工作原理
HDFS写文件流程
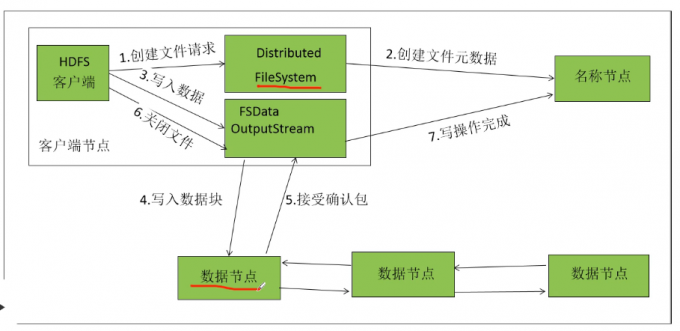

1 | Client客户端发送上传请求,通过RPC与NameNode建立通信,NameNode检查该用户是否有上传权限,以及上传的文件是否在HDFS对应的目录下重名,如果这两者有任意一个不满足,则直接报错,如果两者都满足,则返回给客户端一个可以上传的信息; |
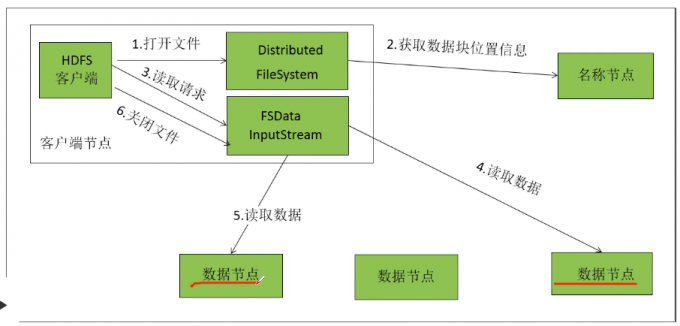
HDFS读文件流程
HDFS容错

NameNode出错

DataNode出错

数据出错

1 | Client向NameNode发送RPC请求。请求文件block的位置; |
HDFS的高级功能
安全模式

回收站

快照

配额

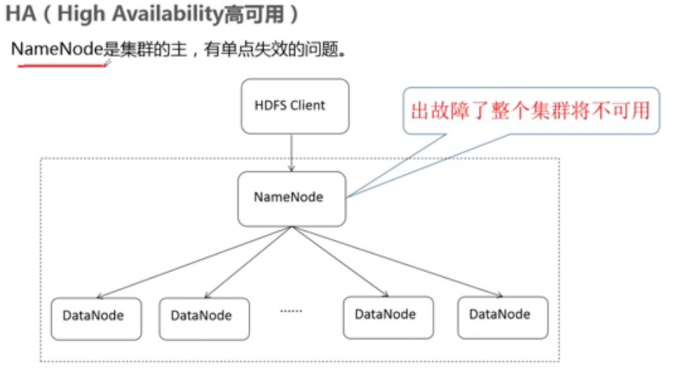
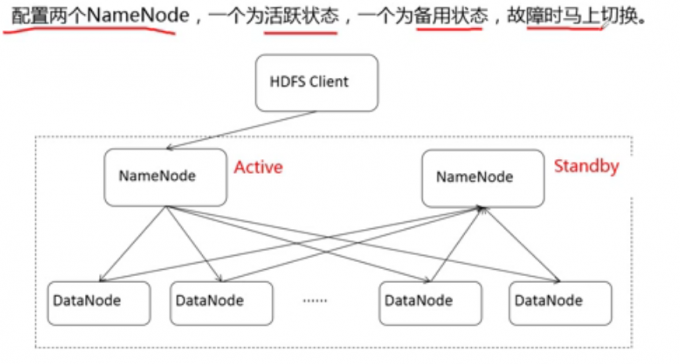
HA(High Availability高可用)
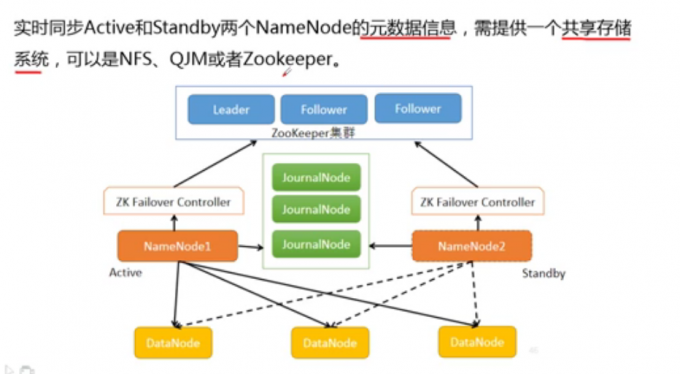
联邦Federation
HDFS使用过程存在的问题

什么是Federation

联邦的优点

HA与Federation的区别

直道相思了无益,未妨惆怅是清狂。

