大数据开发工程师-第四周 第二章NameNode进阶
SecondaryNameNode介绍
1 | 刚才在分析edits日志文件的时候我们已经针对SecondaryNameNode做了介绍,在这里再做一个总结,以示重视。 |
DataNode介绍
1 | DataNode是提供真实文件数据的存储服务 |
block
1 | datanode中数据的具体存储位置是由dfs.datanode.data.dir来控制的,通过查询hdfs-default.xml可以知道,具体的位置在这里 |
1 | 那我们连接到bigdata02这个节点上去看一下 //注意!!! |
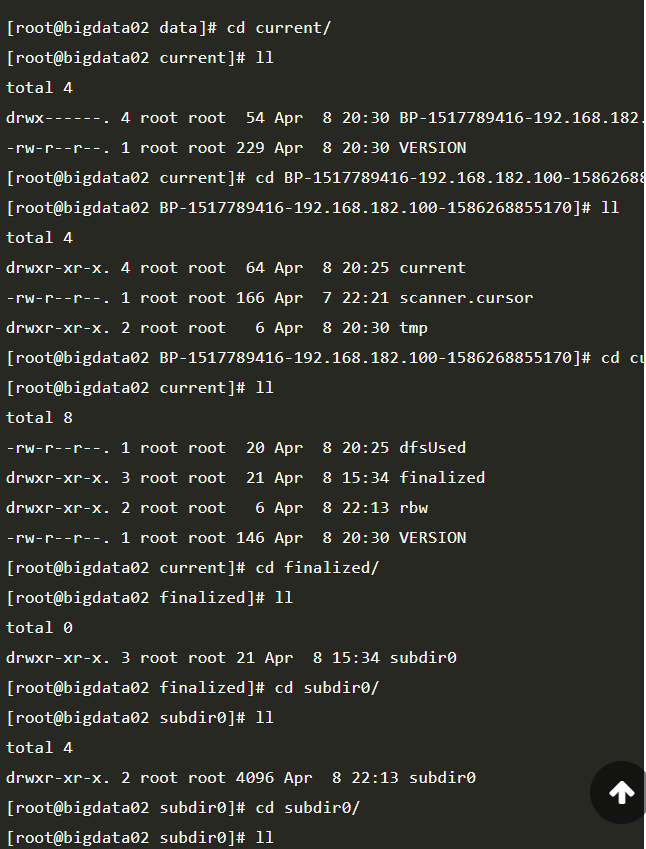
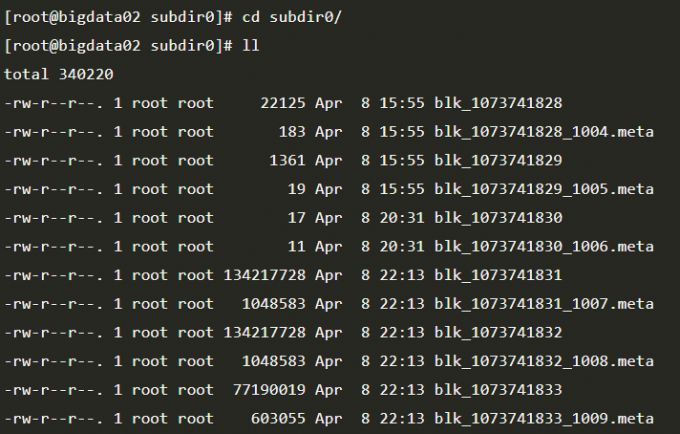
1 | 这里面就有很多的block块了, |
1 | 注意:这个block中的内容可能只是文件的一部分,如果你的文件较大的话,就会分为多个block存储,默认 hadoop3中一个block的大小为128M。根据字节进行截取,截取到128M就是一个block。如果文件大小没有默认的block块大,那最终就只有一个block。 |
replication
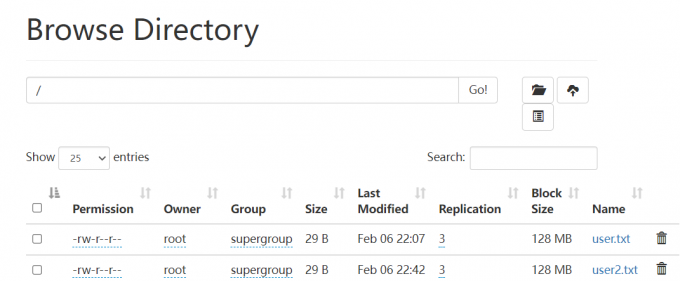
1 | 下面看一下副本,副本表示数据有多少个备份 |
NameNode总结
1 | 注意:block块存放在哪些datanode上,只有datanode自己知道,当集群启动的时候,datanode会扫描自己节点上面的所有block块信息,然后把节点和这个节点上的所有block块信息告诉给namenode。这个关系是每次重启集群都会动态加载的【这个其实就是集群为什么数据越多,启动越慢的原因】 |
1 | 咱们之前说的fsimage(edits)文件中保存的有文件和block块之间的信息。 |
1 | 所以说 其实namenode中不仅维护了文件和block块的信息 还维护了block块和所在的datanode节点的信息。 |
1 | 注意了,刚才我们说了NameNode启动的时候会把文件中的元数据信息加载到内存中,然后每一个文件的元数据信息会占用150字节的内存空间,这个是恒定的,和文件大小没有关系,咱们前面在介绍HDFS的时候说过,HDFS不适合存储小文件,其实主要原因就在这里,不管是大文件还是小文件,一个文件的元数据信息在NameNode中都会占用150字节,NameNode节点的内存是有限的,所以它的存储能力也是有限的,如果我们存储了一堆都是几KB的小文件,最后发现NameNode的内存占满了,确实存储了很多文件,但是文件的总体大小却很小,这样就失去了HDFS存在的价值 |

1 | TextInputFormat是FileInputFormat的子类 |








1 | 最后,在datanode的数据目录下面的current目录中也有一个VERSION文件 |
1 | datanode的VERSION文件 |

