NameNode介绍
1 | 首先是NameNode,NameNode是整个文件系统的管理节点 |
1 | 这些文件所在的路径是由hdfs-default.xml的dfs.namenode.name.dir属性控制的 |
1 | 那我们来看一下这个文件中的dfs.namenode.name.dir属性 |
1 | 进入到/data/hadoop_repo/dfs/name目录下 |
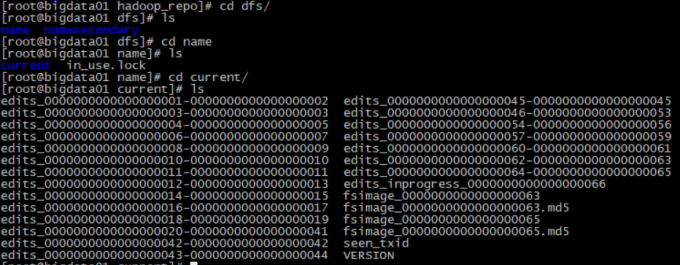
1 | current里面有edits文件和fsimage文件 |
fsimage文件
1 | -i 输入文件 -o 输出文件 |
1 | <inode><id>16393</id><type>FILE</type><name>LICENSE.txt</name><replication>2</replication><mtime>1586332513657</mtime><atime>1586332513485</atime><preferredBlockSize>134217728</preferredBlockSize><permission>root:supergroup:0644</permission><blocks><block><id>1073741827</id><genstamp>1003</genstamp><numBytes>150569</numBytes></block> |
1 | 里面最外层是一个fsimage标签,看里面的inode标签, |
edits文件
1 | 下面我们来看一下edits文件,这些文件在这称之为事务文件,为什么呢? |
1 | 这个edits.xml中可以大致看一下,里面有很多record。每一个record代表不同的操作, |
1 | <RECORD> |
1 | 这里面的每一个record都有一个事务id,txid,事务id是连续的,其实一个put操作会在edits文件中产生很多的record,对应的就是很多步骤,这些步骤对我们是屏蔽的。 |
1 | 注意,这个其实是框架去做的,在合并的时候会对edits中的内容进行转换,生成新的内容,其实edits中保存的内容是不是太细了,单单一个上传操作就分为了好几步,其实上传成功之后,我们只需要保存文件具体存储的block信息就行了把,所以在合并的时候其实是对edits中的内容进行了精简。 |
1 | 他们具体合并的代码我们不用太过关注,但是我们要知道是那个进程去做的这个事情, |
seentxid文件

1 | current目录中还有一个seentxid文件,HDFS format之后是0,它代表的是namenode里面的edits*文件的尾数,namenode重启的时候,会按照seen_txid的数字,顺序从头跑edits_0000001~到seen_txid的数字。如果根据对应的seen_txid无法加载到对应的文件,NameNode进程将不会完成启动以保护数据一致性。 |
VERSION文件
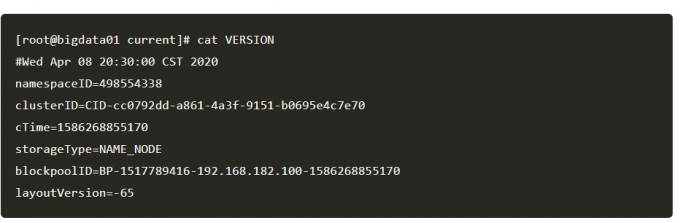
1 | 这里面显示的集群的一些信息、当重新对hdfs格式化 之后,这里面的信息会变化。 |
总结
1 | fsimage: 元数据镜像文件,存储某一时刻NameNode内存中的元数据信息,就类似是定时做了一个快照操作。【这里的元数据信息是指文件目录树、文件/目录的信息、每个文件对应的数据块列表】 |

