第五周 第四章 精讲Shuffle执行过程及源码分析输入输出
Shuffle过程详解
1 | 咱们前面简单说过,shuffer是一个网络拷贝的过程,是指通过网络把数据从map端拷贝到reduce端的过程,下面我们来详细分析一下这个过程 |
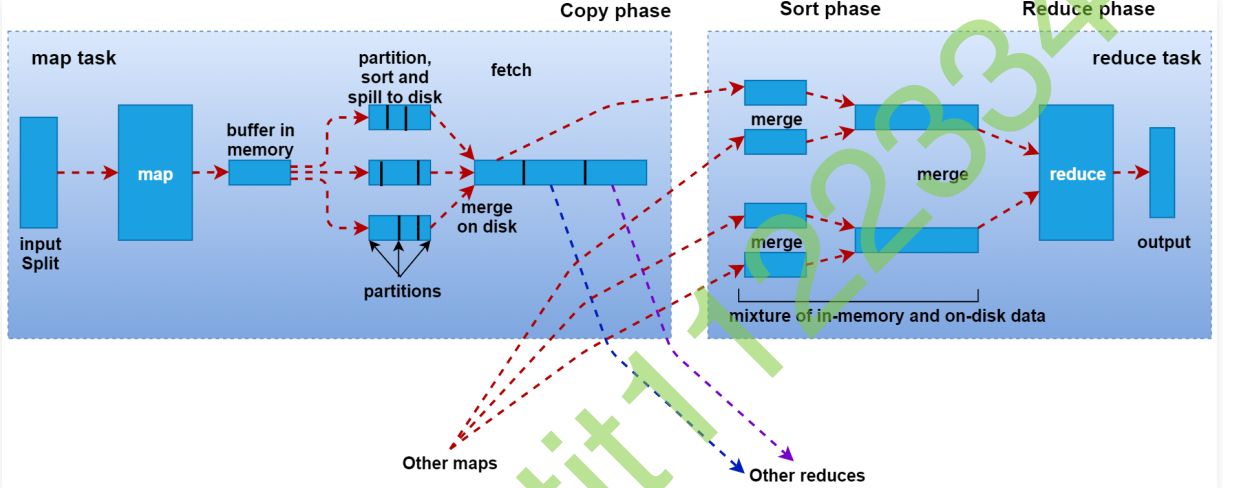
1 | 接下来我们来根据这张图分析一下shuffle的一些细节信息, |
Hadoop中序列化机制
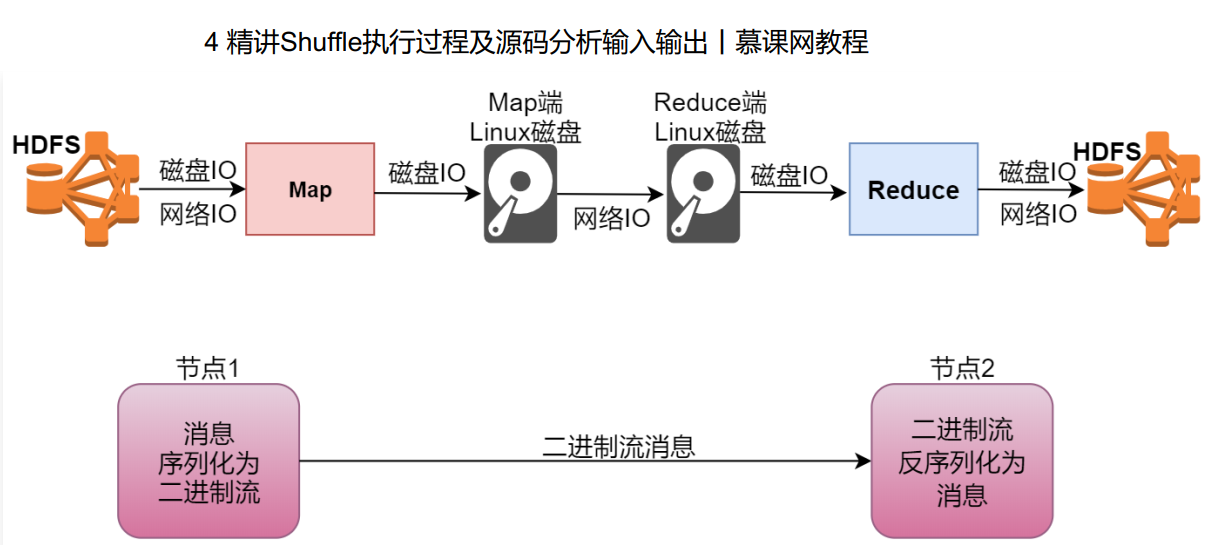
1 | 我们的map阶段在读取数据的是需要从hdfs中读取的,这里面需要经过磁盘IO和网络IO,不过正常情况下map任务会执行本地计算,也就是map任务会被分发到数据所在的节点进行计算,这个时候,网络io几乎就没有了,就剩下了磁盘io,再往后面看,map阶段执行完了以后,数据会被写入到本地磁盘文件,这个时候也需要经过磁盘io,后面的shuffle拷贝数据其实也需要先经过磁盘io把数据从本地磁盘读出来再通过网络发送到reduce节点,再写入reduce节点的本地磁盘,然后reduce阶段在执行的时候会经过磁盘io读取本地文件中的数据,计算完成以后还会经过磁盘io和网络io把数据写入到hdfs中。 |
1 | 那我们来看一下Hadoop中提供的常用的基本数据类型的序列化类 |
hadoop自己实现的序列化的特点
1 | 1. 紧凑: 高效使用存储空间 |
java中序列化的不足
1 | 1. 不精简,附加信息多,不太适合随机访问 |
实战(序列化)
1 | 前面我们分析了Java中的序列化和Hadoop中的序列化,其实最主要的区别就是针对相同的数据,Java中的序列化会占用较大的存储空间,而Hadoop中的序列化可以节省很多存储空间,这样在海量数据计算的场景下,可以减少数据传输的大小,极大的提高计算效率 |
java序列化对象
1 | package com.imooc.mc; |
hadoop序列化对象
1 | package com.imooc.mc; |
1 | 执行这两个代码,最终会在D盘下产生两个文件,查看这两个文件的大小,最终发现Java序列化的文件大小是Hadoop序列化文件大小的10倍左右。 |
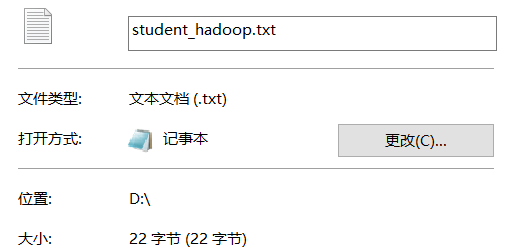
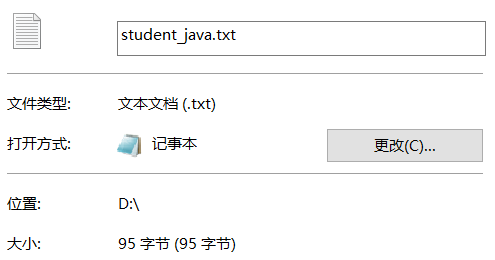
小结
1 | 1.IDEA快速编写属性对应的方法 |
InputFormat分析
InputFormat
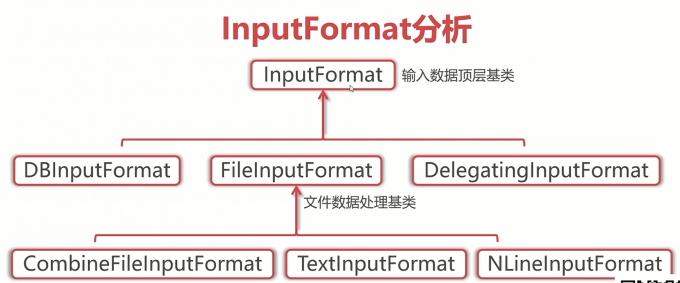
1 | Hadoop中有一个抽象类是InputFormat,InputFormat抽象类是MapReduce输入数据的顶层基类,这个抽象类中只定义了两个方法: |
InputFormat的子类
1 | 这个抽象类下面有三个子继承类, |
FileInputFormat的子类
1 | FileInputFormat下面还有一些子类: |
详细分析一下getSplits方法的具体实现代码
下载源码 hadoop-3.2.2-src.tar.gz
解压
1 | 将D:\code\IDEA\hadoop-3.2.2-src\hadoop-mapreduce-project\hadoop-mapreduce-client\hadoop-mapreduce-client-core作为IDEA的项目 |
下载依赖
1 | 1.将maven的配置文件里加上镜像,这样下载依赖会快些 |
getsplits源码剖析
1 | 需要将项目里的java文件夹设置为root source(选中后右键mark as),这样设置后查看源码ctrl 左键 才会快速关联 |
小结
1 | SPLIT_SLOP=1.1 |
面试题
1 | 1. 一个1G的文件,会产生多少个map任务? 8 |
实战140 141
生成140 141大小的文件
1 | package com.imooc.mc; |
打jar包,上传数据到hdfs,提交任务到集群
结果查看
141

140

createRecordReader方法
看TextInputFormat对这个方法的实现
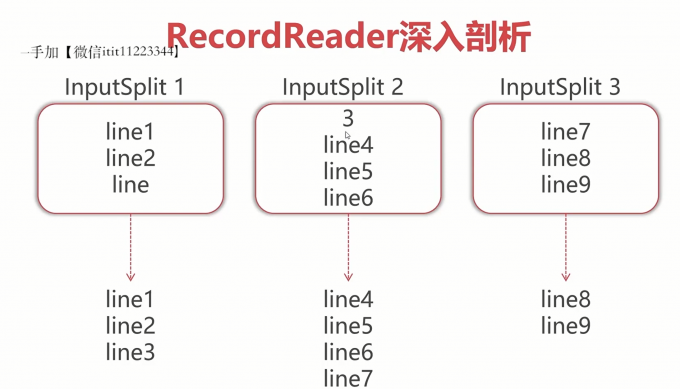
1 | 注意:如果这个InputSplit不是第一个InputSplit,我们将会丢掉读取出来的第一行 |
OutputFormat分析
1 | 前面我们分析了InputFormat,下面我们来分析一下OutputFormat,顾名思义,这个是控制MapReduce输出的 |
1 | 这几个其实和InputFormat中的那几个文本处理类是对应着的,当然了针对输出数据还有其它类型的处理 |

