第五周 第三章 深入 MapReduce
MapReduce任务日志查看
1 | 如果想要查看mapreduce任务执行过程产生的日志信息怎么办呢? |
开启yarn的日志聚合功能方式
自定义日志
map函数修改
1 | protected void map(LongWritable k1, Text v1, Context context) |
reduce函数修改
1 |
|
打包,上传,提交任务到集群
结果查看
1 | 等待任务执行结束,我们发现在控制台上是看不到任务中的日志信息的,为什么呢?因为我们在这相当于是通过一个客户端把任务提交到集群里面去执行了,所以日志是存在在集群里面的。想要查看需要需要到一个特殊的地方查看这些日志信息 |
打开日志聚合功能
1 | 那我们就来开启日志聚合功能。开启日志聚合功能需要修改yarn-site.xml的配置,增加 |
1 | 添加部分 |
1 | 启动historyserver进程,需要在集群的所有节点上都启动这个进程 |
1 | 此时再进入yarn的8088界面,点击任务对应的history链接就可以打开了。 |

1 | 想要查看reduce输出的日志信息需要到reduce里面查看,操作流程是一样的,可以看到k2,v2和k3,v3的 |

使用logger
1 | 咱们刚才的输出是使用syout输出的,这个其实是不正规的,标准的日志写法是需要使用logger进行输出的 |
修改map函数
1 | public static class myMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ |
修改reduce函数
1 | public static class myReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ |
打包,上传,提交任务到集群
1 | 重新编译打包上传,重新提交最新的jar包,这个时候再查看日志就需要到Log Type: syslog中查看日志了。 |
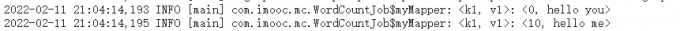

1 | 这是工作中比较常用的查看日志的方式,但是还有一种使用命令查看的方式,这种方式面试的时候一般喜欢问 |
面试爱问的日志查看方式(面试)
1 | yarn logs -applicationId application_158771356 | grep k1,v1 |
1 | 这种方式也需要大家能够记住并且掌握住,首先是面试的时候可能会问到,还有就是针对某一些艰难的场景下,无法使用yarn的web界面查看日志,就需要使用yarn logs命令了 |
停止Hadoop集群中的任务
1 | 如果一个mapreduce任务处理的数据量比较大的话,这个任务会执行很长时间,可能几十分钟或者几个小时都有可能,假设一个场景,任务执行了一半了我们发现我们的代码写的有问题,需要修改代码重新提交执行,这个时候之前的任务就没有必要再执行了,没有任何意义了,最终的结果肯定是错误的,所以我们就想把它停掉,要不然会额外浪费集群的资源,如何停止呢? |
1 | [root@bigdata01 hadoop-3.2.0]# yarn application -kill application_15877135678 |


MapReduce程序扩展
1 | 咱们前面说过MapReduce任务是由map阶段和reduce阶段组成的但是我们也说过,reduce阶段不是必须的,那也就意味着MapReduce程序可以只包含map阶段。 |
map阶段编写
1 | public static class myMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ |
main编写
1 | public static void main(String[] args){ |
打包,上传,提交到集群,结果查看

1 | 这里发现map执行到100%以后任务就执行成功了,reduce还是0%,因为就没有reduce阶段了。 |



