Mapreduce
MapReduce概述
MapReduce是什么?
Mapreduce是一种简化并行计算的编程模型,用于进行大数据量的计算
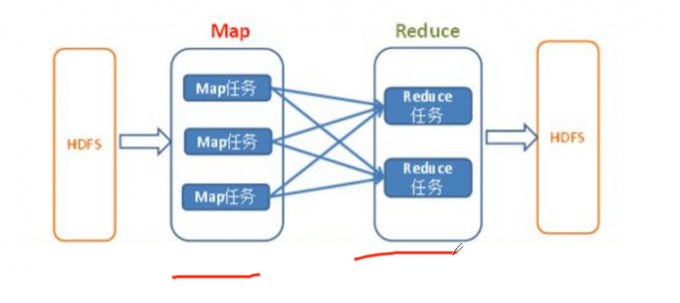
MapReduce设计思想

MapReduce特点
易于编程
良好的扩展性
高容错性
擅长对PB级以上海量数据进行离线处理
MapReduce不擅长的场景
实时计算
MapReduce无法像MySQL一样,在毫秒或秒级内返回结果
流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,动态变化
DAG(有向图)计算
MapReduce编程模型
初识MapReduce模型
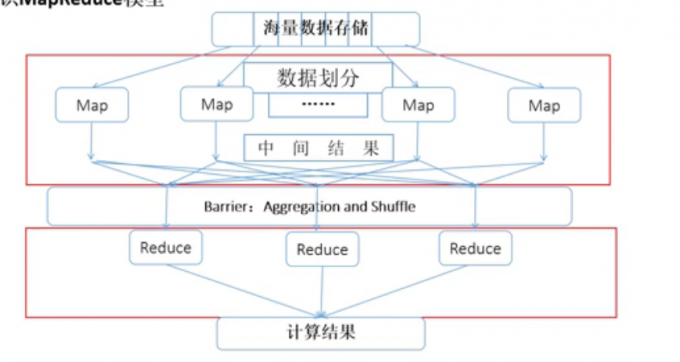

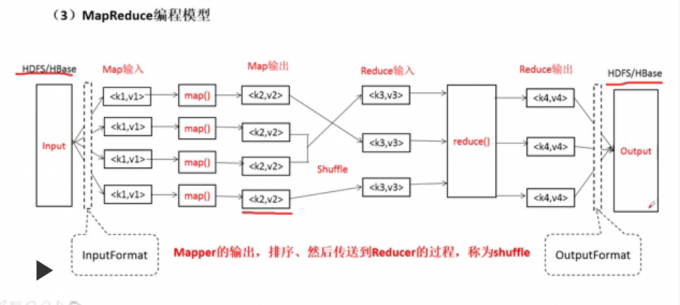
MR原语: 相同的key为一组,调用一次reduce方法,迭代计算这一组数据
MapReduce工作流程

MapReduce模型要点

案例
案例一
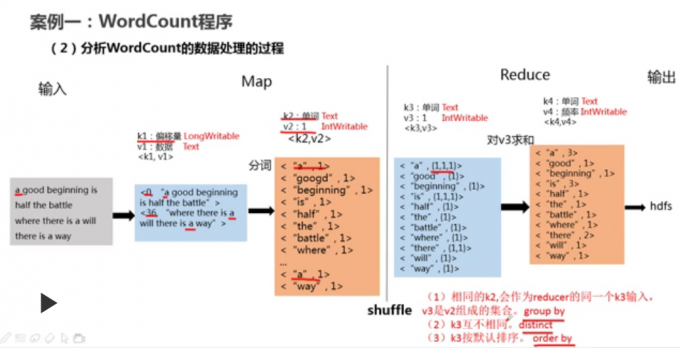
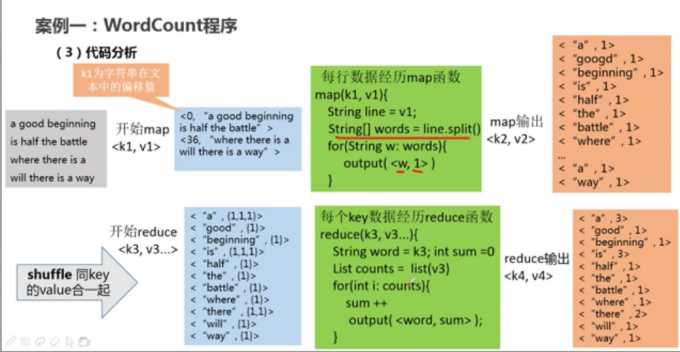
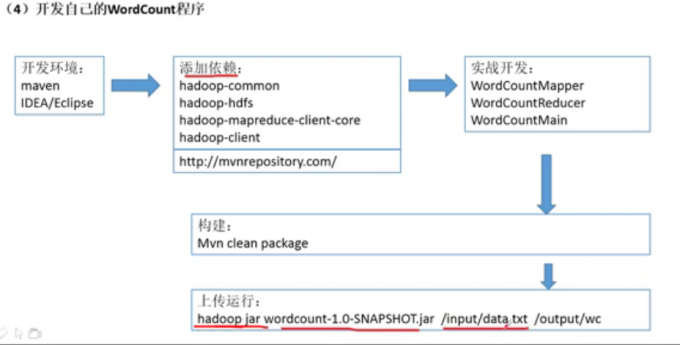


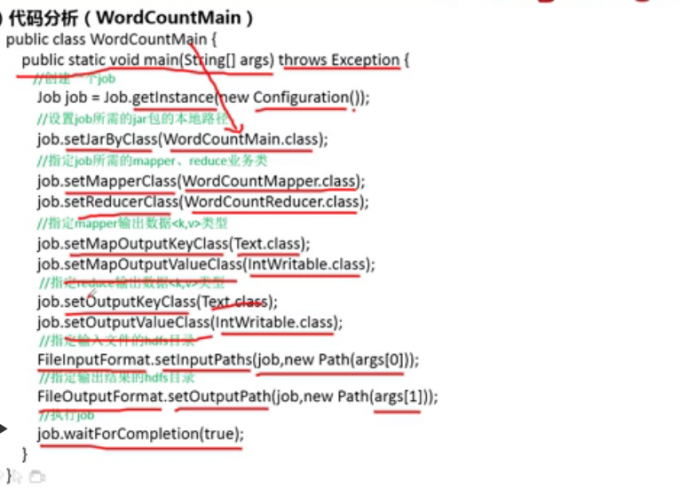
案例二
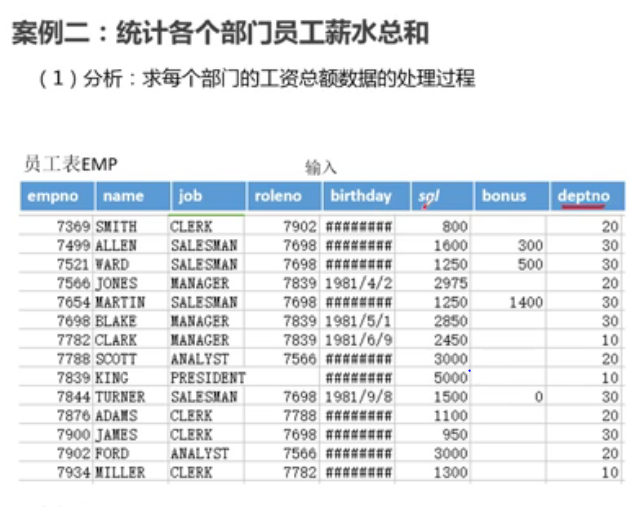



案例三 (序列化)
序列化和反序列化


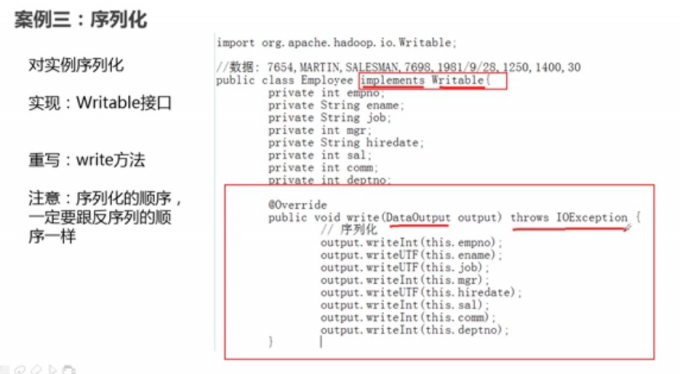
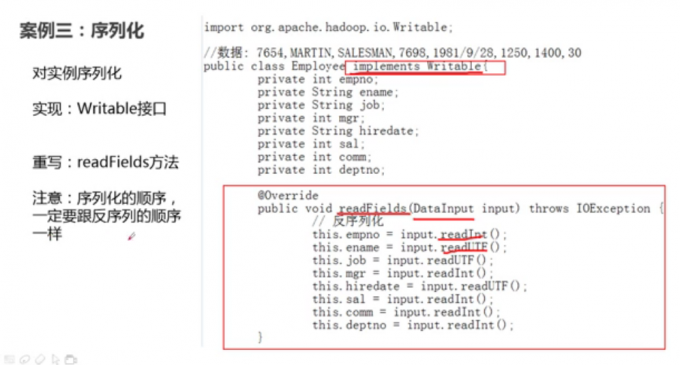
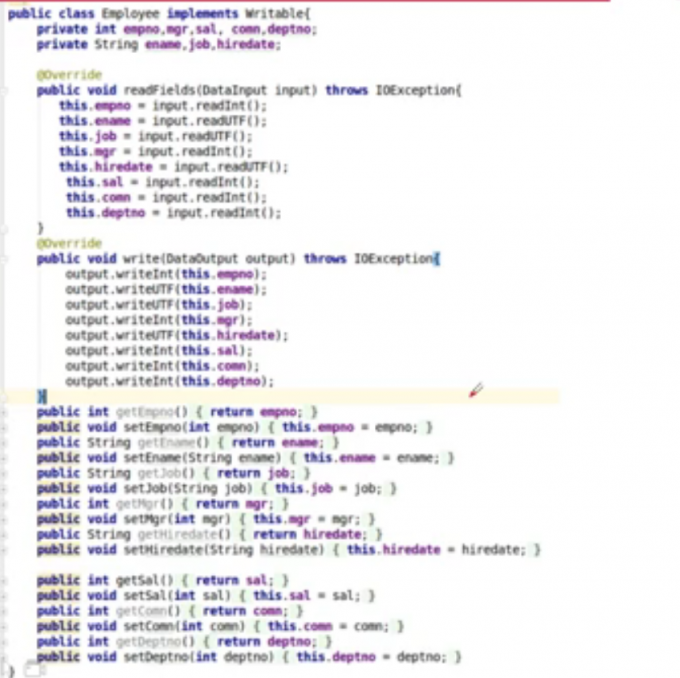
Mapper
1 | package serializable.mapreduce; |
Reducer
1 | package serializable.mapreduce; |
main
1 | package serializable.mapreduce; |
MapReduce进阶
mapreduce的输入格式
物理分片
分割会严格按照设定大小128m或字数分割,可能会造成不符合逻辑的分割
逻辑分片
1 | WordCount 程序的 main()方法中,可以通过下面的语句指定输入格式,也可以不 |
inputFormat提供一下两个功能:
- 数据切分,获得SplitInput(逻辑切片) ,FileInputFormat.getSplits()获取到。
- 为Mapper提供输入数据
有多少个SplitInput,就有多少个Mapper
TextInputFormat 是默认InputFormat
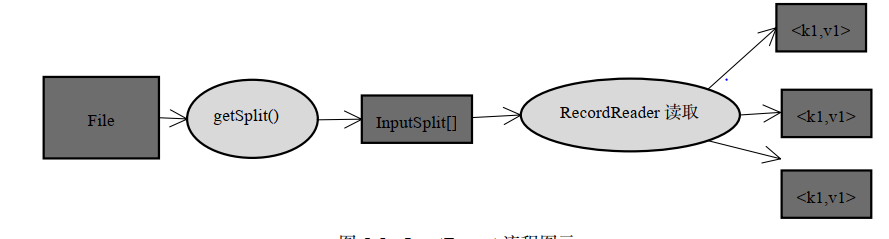
getSplits 方法负责将一个大数据逻辑分成许多片,但每个分片只是一个逻辑上的定义,仅是提供了一个如何将数据分片的方法,并没有物理上的独立存储
createRecordReader 方法返回一个 RecordReader 对象,实现了类似的迭代器功能,将某个InputSplit 解析成一个个 key/value 对
定位记录边界
为了能识别一条完整的记录,应该添加一些同步标示,如 TextInputFormat 的标示是换行符
InputFormat 接口实现类
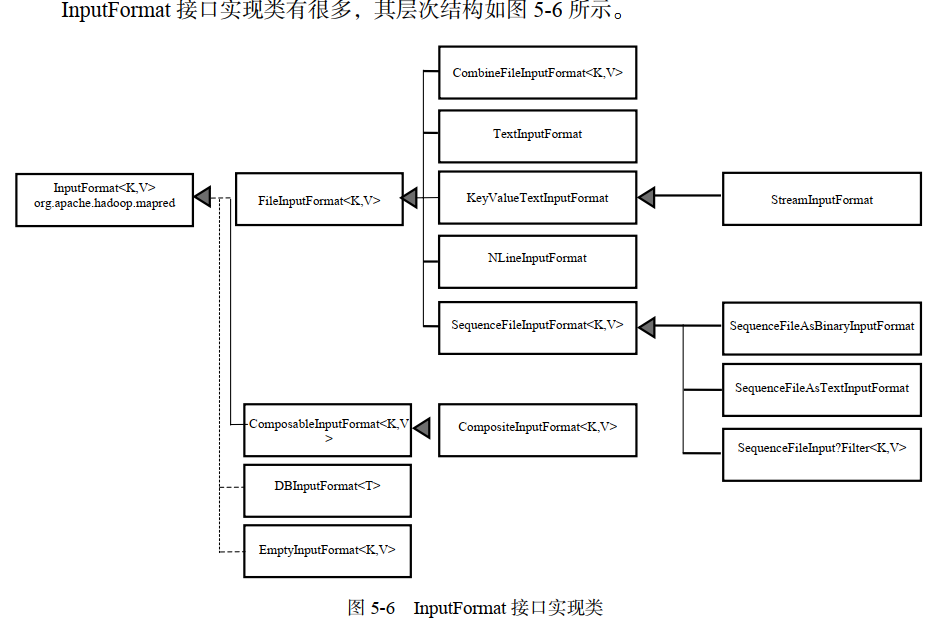
1 | 这里介绍一下 FileInputFormat。FileInputFormat 是所有文件作为其数据源的 InputFormat实现的基类,它的主要作用是指出作业的输入文件位置。因为作业的输入被设定为一组路径,这对指定作业输入提供了很强的灵活性。FileInputFormat 提供了如下 4 种静态方法来设定作业的输入路径。 |
1 | 这些方法都是 `FileInputFormat` 类中用来设置 MapReduce 作业输入数据路径的静态方法。它们的区别在于接受的参数类型和数量不同。 |
mapreduce的输出格式
outputFormat接口
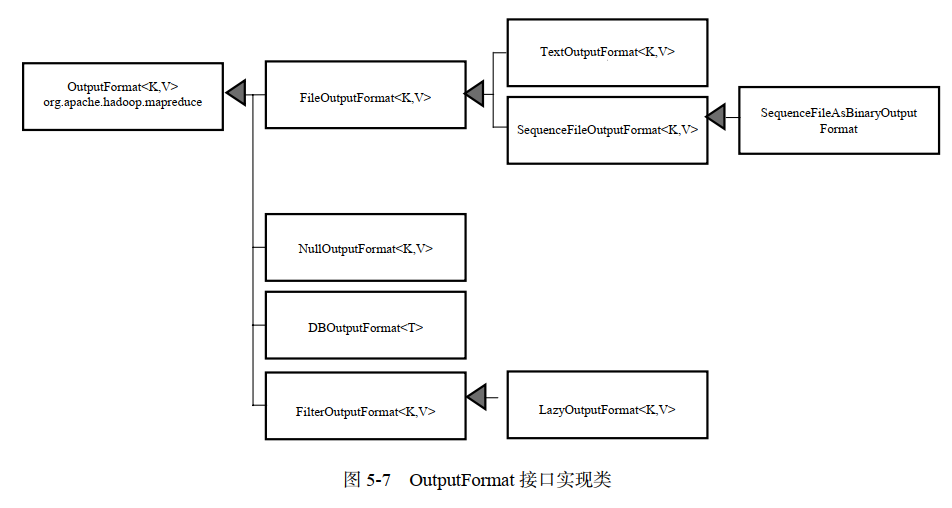
OutputFormat主要用于描述输出数据的格式,通过RecordWriter能够将用户提供的key/value对写入特定格式的文件中
(1)TextOutputFormt调用toString()方法把它们转换为字符串
(2)NullWritable来省略输出的key或value
outputFormat接口实现类
排序:排序是针对map输出里面的key,没会对value排序;map输出和reduce输入都有排序;作用是提高效率
分区Partition
Partition定义:
Mapper任务划分数据的过程称作Partition。
负责实现数据的类称作Partitioner,默认的分区是Hash分区 (Hash Partition)
Partition作用:
将map阶段产生的所有<key,value>对分配给不同的Reducer 处理,可以将Reduce阶段的处理负载进行分摊
Partition的数量决定Reducer的数量
Hash分区基本原理
计算某个值的hash值,如果结果相同,则放入同一个分区
Hash分区的作用:把数据打散进行存放,最终是为了避免热块
实例
Mapper
1 | package part; |
Reducer
1 | package part; |
Patitioner
1 | package part; |
Main
1 | package part; |
合并Combiner
减少Mapper输出到Reduce的数据量,缓解网络传输瓶颈,提高reducer的执行效率
需要注意的问题:一定要谨慎使用Combiner
有些情况不能使用Combiner —-> 如:求平均值
保证引入Combiner以后,不能改变原来的逻辑


1 | 若要引入 Combiner,只需要在 WordCount 程序的 main()方法中,增加下面语句即可。 |
MapReduce的工作机制
MapReduce 作业的运行机制
1 | MapReduce |
1 | 本小节将揭示Hadoop运行作业时所采取的措施,整个过程描述如图5-11所示。在最高层,有以下5个独立的实体。 |

1 | MapReduce 在 YARN 中的运行过程大致分为如下 11 步,如图 5-11 所示。 |
进度和状态的更新
1 | Map 任务或 Reduce 任务运行时,子进程和自己的 Application Master 进行通信。每隔 3 秒 |

1 | 状态更新在 MapReduce 系统中的传递流程可总结为如下几步。 |
Shuffle
1 | MapReduce 确保每个 Reducer 的输入都是按键排序的。系统执行排序、将 Mapper 输出作为 |

1.Map 端
1 | (1)写入缓冲区。map 函数开始产生输出时,并不是简单地将它写入磁盘,而是先写入一个 |
2.Reduce 端
1 | (1)复制文件。Reducer通过HTTP得到输出文件的分区。如果Map输出相当小,会被复制到Reduce任务JVM的内存。否则,Map输出被复制到磁盘。一旦内存缓冲区达到阈值大小(由mapreduce.reduce.shuffle.merge.percent决定)或达到Map输出阈值(由mapreduce.reduce.merge.inmem.threshold 控制),则合并后溢写入磁盘。如果指定Combiner,则在合并期间运行它以降低写入磁盘的数据量。 |
如果今天后悔昨天,那么明天就会后悔今天。

