第八章-基于python的数据整理
合并多个数据集
pandas提供以下几种方法合并多个数据集:
pandas.merge:基于一个键或多个键连接多个DataFrame的行
pandas.concat:按行或按列将不同的对象叠加到一起
combine_first:使用一个对象中的数据填充另一个对象中对应位置的缺失值
merge
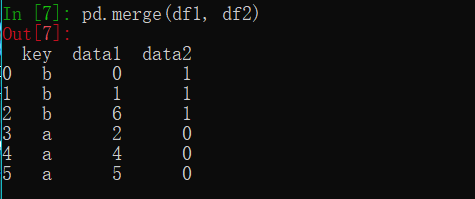
默认连接为类似sql的inner join操作
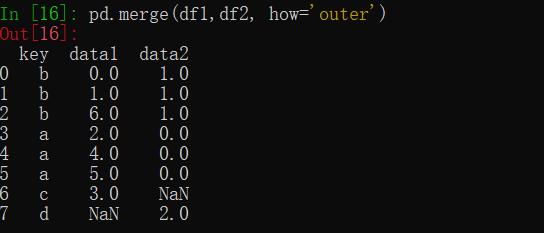
利用how参数,实现其它连接方式,left join, right join, outer join
不指明使用某一列作为连接键
在这种情况下使用重叠列作为键进行连接
1 | from pandas import DataFrame |
指明连接键
1 | // 等同于上例 |
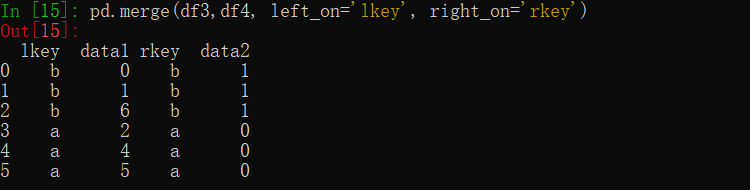
使用不同名的键连接
1 | df3 = DataFrame({'lkey':['b','b', 'a', 'c', 'a','a', 'b'], 'data1':range(7)}) |
how参数
1 | pd.merge(df1, df2, how='outer') |
使用多个键连接
1 | left = DataFrame({'key1':['foo', 'foo', 'bar'], |

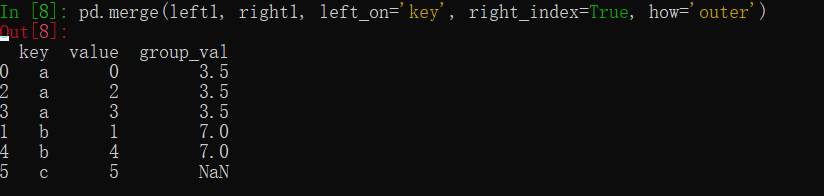
使用index进行DataFrame合并
1 | left1=DataFrame({'key':['a', 'b', 'a', 'a', 'b', 'c'], |
沿着横轴或纵轴串接
numpy的concatenate函数
NumPy库的concatenate函数用于串接起NumPy的原生数组
axis参数默认为0,沿着竖轴连接
1 | import numpy as np |

pandas的concat函数
用于Series数据类型
1 | s1 = Series([0,1], index=['a','b']) |
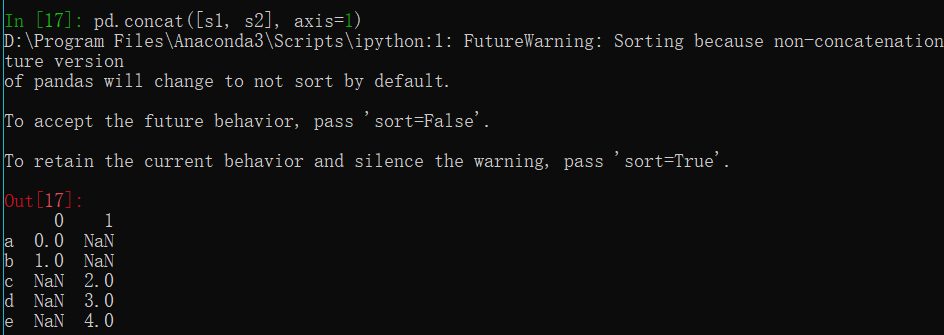
可以通过join参数修改连接方式
1 | s1 = Series([0,1], index=['a','b']) |
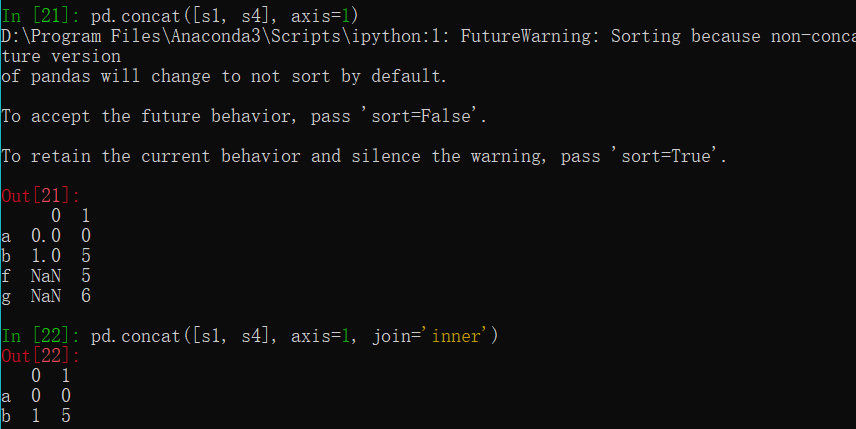
用于DataFrame数据类型
1 | df1 = DataFrame(np.arange(6).reshape(3,2),index=['a','b','c'],columns=['one', 'two']) |
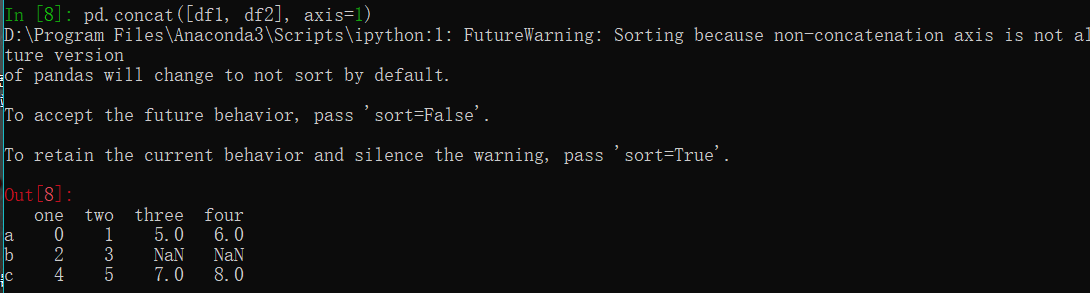
数据重塑
数据重塑:是指转换输入的数据结构,使其适合后续的分析
pandas提供了数据重塑的基本操作,这些操作被用于二维度表格数据
多级索引数据的重塑
DataFrame可以设置多级索引。对于多级索引的数据,pandas的stack方法将数据集的列旋转为行
stack
1 | data=DataFrame(np.arange(6.reshape((2,3)),index=pd.Index(['ohio','colorado'], name='state'), columns=pd.Index(['one','two','three'], name='number')) |
unstack
1 | result = data.stack() |
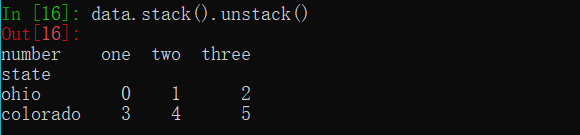
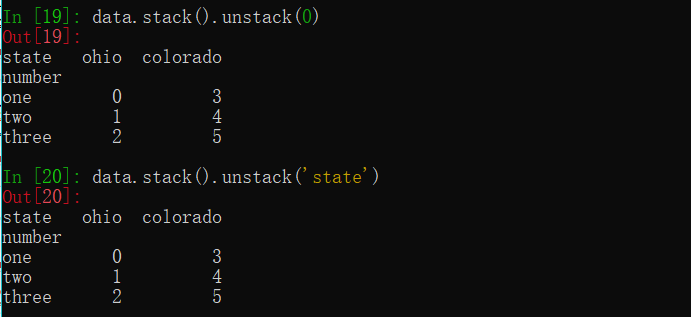
默认情况下转换内层级别索引,通过传递一个级别的标号或级别的别称,可以指定要转换的级别,以下两种操作方式:
1 | result.unstack(0) |
1 | result.unstack('state') |
应用pivot方法重塑数据
数据转换
移除重复数据
这两个方法默认以整行判断,也可以指定进行部分列判断重复
duplicated()
判断是否重复,返回一个bool型series
1 | data = DataFrame({'k1':['zhongxing','Huawei']*3+['Huawei'], 'k2':[1,1,2,3,3,4,4]}) |

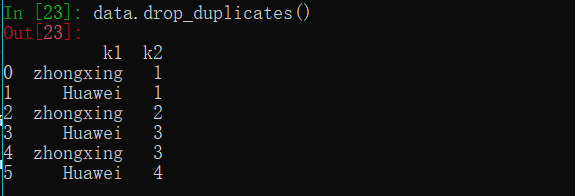
drop_duplicates()
删除重复行
1 | data.drop_duplicates() |