数据查询
单表查询
选择表中若干列
指定列
1 | SELECT sno,sname |

全部列
1 | SELECT * |

查询计算过得值
1 | SELECT子句的<目标列表达式〉不仅可以是表中的属性列,也可以是表达式 |
目标表达水不仅可以是算数表达式,也可以是字符串常量,函数等
修改查询列标题
用户可以通过指定别名来改变查询结果的列标题,这对于含算术表达式、常量、函数名的目标列表达式尤为有用
1 | SELECT Sname [AS] newName |
选择表中的若干元组
系统查询的思路是,将关系中的所有元组一一进行条件匹配,然后在输出。当数据量大时,这种思路就不太合适了。可以创建索引解决
消除重复行
1 | SELECT DISTINCT Sno |
查询满足条件的元组
通过WHERE来实现
查询条件:

1 | SELECT Sname,Sdept,Sage |
注意:’IS’ 有时不能用‘=’代替,如’IS NULL’
字符匹配时,可以有通配符,如下:
_
代表任意单个字符
%
任意长度的字符,零个也包括
当数据中本身就有通配符时,就需要用到ESCAPE ‘<换码字符>’
1 | SELECT Cno,Credit |
ORDER BY子句
默认升序ASC
1 | SELECT Sno, Grade |
可以既有升序又有降序:
1 | SELECT A, B |
1 | 在使用 GROUP BY 子句进行分组后,可以使用 ORDER BY 子句对分组后的结果进行排序。不过,需要注意的是,ORDER BY 子句只能对分组后的结果进行排序,而不能对每个分组内部的数据进行排序。 |
1 | CREATE TABLE Orders ( |
TOP
TOP N
1 | SELECT TOP N * |
TOP N PERCENT
1 | SELECT TOP N PERCENT * |
聚集函数
聚集函数中除COUNT外,其它函数在计算过程中均省略NULL;WHERE子句中不能使用聚集函数
COUNT()
COUNT(*) 统计元组个数
COUNT( [DISTINCT|ALL] <列名>) 统计一列中值的个数
SUM()
SUM( [DISTINCT|ALL] <列名>) 计算一列值的总和(此列必须是数值型)
AVG( [DISTINCT|ALL] <列名>) 计算一列值的平均值(此列必须是数值型)
MAX
MAX( [DISTINCT|ALL] <列名>) 求一列值中的最大值
MIN
MIN( [DISTINCTIALL] <列名>) 求一列值中的最小值
GROUP BY子句
GROUP B Y 子句将查询结果按某一列或多列的值分组,值相等的为一组。
分组后聚集函数将作用于每一个组,即每一组都有一个函数值。
如果分组后还要求按一定的条件对这些组进行筛选,最终只输出满足指定条件的组,则可以使用HAVING短语指定筛选条件。
WHERE子句与HAVING短语的区别在于作用对象不同。 WHERE子句作用于基本表或视图,从中选择满足条件的元组。 HAVING短语作用于组,从中选择满足条件的组
WHERE子句中是不能用聚集函数作为条件表达式的
1 | /*查询课程号及相应选课人数*/ |
1 | /*查询选取三门课程以上的学生学号*/ |
1 | /*查询平均成绩大于等于90 分的学生学号和平均成绩。*/ |
不一定是group by 单个属性
1 | where子句中也不能有group by |
连接查询
等值与非等值连接
连接查询的WHERE子句中用来连接两个表的条件称为连接条件或连接谓词,其一般格式为 :
1 | [<表名1>.] <列名l> <比较运算符> [<表名2>.] <列名2> |
当连接运算符为=时,称为等值连接。使用其他运算符称为非等值连接。
这就是嵌套循环连接算法: 一个表的全部元组的某个属性一一去和另一个元组的某个属性进行比较
等值连接
1 | SELECT Student.*, SC.* |
结果中两个Sno都存在
一 条 SQ L语句可以同时完成选择和连接查询,这 时 WHERE子句是由连接谓词和选择谓词组成的复合条件。
自然连接
若在等值连接中把目标列中重复的属性列去掉则为自然连接。
1 | SELECT Student.Sno, Sname, Ssex, Sage, Sdept, Cno, Grade |
结果只保留一个Sno
自身连接
Course表取两个别名,一个是 F IR S T ,另一个是SECOND。
1 | SELECT FIRST.Cno,SECOND.Cpno |
外连接
有 时 想 以 Student表为主体列出每个学生的基本情况及其选课情况。若某个学生没有选课,仍 把 Student的悬浮元组保存在结果关系中,而 在 S C 表的属性上填空值NULL ,这时就需要使用外连接
1 | SELECT Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade |
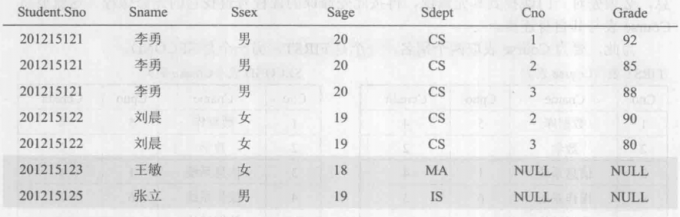
左外连接列出左边关系(如本例Student)中所有的元组,右外连接列出右边关系中所有的元组。
多表连接
1 | SELECT Student.Sno,Sname,Cname,Grade |
XXX INNER JOIN XXX ON(…..)
1 | SELECT * |
例题
1 | -- 查询每门课程的被选修情况和课程的名字。 |
1 | -- 查询选修了课程的学生姓名 |
嵌套查询
在 SQL语言中,一 个 SELECT-FROM-WHERE语句称为一个查询块。将一个查询块嵌套在另一个查询块的WHERE子句或 HAVING短语的条件中的查询称为嵌套查询(nested query )
1 | SELECT Sname /*外层查询或父査询*/ |
SQ L语言允许多层嵌套查询,即一个子查询中还可以嵌套其他子查询。需要特别指出的是,子查询的 SELECT语句中不能使用ORDER B Y 子句, ORDER B Y 子句只能对最终查询结果排序。
大多数嵌套查询可以用连接查询代替
带有IN谓词的子查询
在嵌套查询中,子查询的结果往往是一个集合,所 以 谓 词 IN 是嵌套查询中最经常使用的谓词。
1 | SELECT Sno,Sname,Sdept /*例 3.55 的解法一*/ |
本例中,子查询的查询条件不依赖于父查询,称为不相关子查询。如果子查询的查询条件依赖于父查询,这类子查询称为相关子查询(correlated subquery) , 整个查询语句称为相关嵌套查询(correlated nested query) 语句
1 | SELECT Sl.Sno,Sl.Sname,Sl.Sdept /*例 3.55 的解法二 */ |
可见,实现同一个查询请求可以有多种方法,当然不同的方法其执行效率可能会有差别 ,甚至会差别很大。这就是数据库编程人员应该掌握的数据库性能调优技术
1 | SELECT Sno,Sname |
有些嵌套查询可以用连接运算替代,有些是不能替代的





带有比较运算符的子查询
可以用>,<,>=,<=,!=或<>等比较运算符
1 | SELECT Sno ,Cno |
该值是与父查询相关的,因此这类查询称为相关子查询
求解相关子查询不能像求解不相关子查询那样一次将子查询求解出来,然后求解父查询


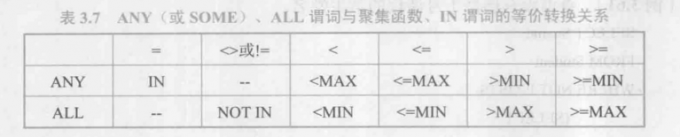
带有ANY(SOME)或ALL谓词的子查询

1 | SELECT Sname,Sage |
用ANY后形成集合
事实上,用聚集函数实现子查询通常比直接用ANY或ALL查询效率要高。ANY,ALL与聚集函数的对应关系如表:



带有EXISTS谓词的子查询
带有EXISTS谓词的子查询不返回任何数据,只产生逻辑真假值TRUE,FALSE
1 | SELECT Sname |
这也是相关子查询。先取一个外层的元组
由 EXISTS引出的子查询,其目标列表达式通常都用**, 因为带 EXISTS的子查询只返回真值或假值,给出列名无实际意义

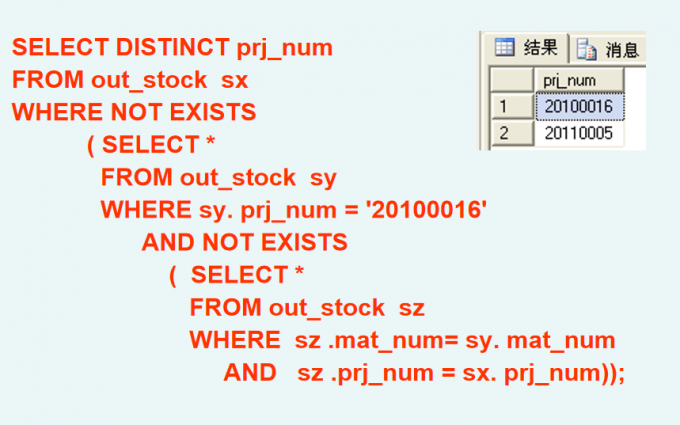
与 EXISTS谓词相对应的是NOT EXISTS谓词。使用存在量词NOT EXISTS后,若内层查询结果为空,则外层的WHERE子句返回真值,否则返回假值
1 | SELECT Sname |
由于带EXISTS量词的相关子査询只关心内层查询是否有返回值,并不需要查具体值,因此其效率并不一定低于不相关子查询,有时是高效的方法
用EXISTS/NOT EXISTS实现全称量词


用EXISTS/NOT EXISTS实现逻辑蕴涵



集合查询
UNION , INTERSECT, EXCEPT
列数相等,对应属性相同
属性名无关,属性名取第一个结果属性名
自动除去重复; 不去重UNION ALL
最后使用ORDER BY(写在最后);可以用数字代替对应第几个属性,ORDER BY 3
UNION并
1 | SELECT Sno |

INTERSECT交
1 | SELECT * |

EXCEPT差
1 | SELECT * |
基于派生表的查询

子查询不仅可以出现在WHERE子句中,还可以出现在FROM 子句中,这时子查询生成的临时派生表(derived table )成为主查询的查询对象

有top的子查询可以把order by放在子查询

1 | SELECT Sno, Cno |
如果子查询中没有聚集函数,派生表可以不指定属性列
通 过 FROM 子句生成派生表时, A S 关键字可以省略,但必须为派生
关系指定一个别名

从此无心爱良夜,任他明月下西楼。

