动态渲染页面爬取-Selenium
1 | 在前一章中,我们了解了Ajax的分析和抓取方式,这其实也是JavaScript动态渲染的页面的一种情形,通过直接分析Ajax, 我们仍然可以借助requests或urllib来实现数据爬取。 |
1 | 不过JavaScript动态渲染的页面不止Ajax这一种。比如中国青年网(详见http://news.youth.cn/gn/),它的分页部分是由JavaScript生成的,并非原始HTML代码,这其中并不包含Ajax请求。比如ECharts的官方实例(详见http://echarts.baidu.eom/demo.html#bar-negative) , 其图形都是经过JavaScript 计算之后生成的。再有淘宝这种页面,它即使是Ajax获取的数据,但是其Ajax接口含有很多加密参数,我 |
Selenium的使用
1 | Selenium是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。对于一些JavaScript动态渲染的页面来说,此种抓取方式非常有效。本节中,就让我们来感受一下它的强大之处吧。 |
准备工作
1 | 本节以Chrome为例来讲解Selenium的用法。在开始之前,请确保已经正确安装好了 Chrome浏览器并配置好了ChromeDriver。另外,还需要正确安装好Python的 Selenium库,详细的安装和配置过程可以参考第1章。 |
基本使用
1 | 准备工作做好之后,首先来大体看一下Selenium有一些怎样的功能。示例如下: |
1 | 运行代码后发现,会自动弹出一个Chrome浏览器。浏览器首先会跳转到百度,然后在搜索框中输入Python ,接着跳转到搜索结果页 |
总结
1 | 1.browser.get_cookies() |
声明浏览器对象
1 | Selenium支持非常多的浏览器,如Chrome、Firefox、Edge等,还有Android, BlackBerry等手机端的浏览器。另外,也支持无界面浏览器PhantomJS |
1 | 此外,我们可以用如下方式初始化: |
访问页面
1 | 我们可以用get()方法来请求网页,参数传入链接URL即可。比如,这里用get()方法访问淘宝,然后打印出源代码,代码如下: |
查找节点
1 | Selenium可以驱动浏览器完成各种操作,比如填充表单、模拟点击等。比如,我们想要完成向某个输入框输入文字的操作,总需要知道这个输入框在哪里吧?而 Selenium提供了一系列查找节点的方 |
单个节点
1 | 比如,想要从淘宝页面中提取搜索框这个节点,首先要观察它的源代码 |
1 | 我们用代码实现一下: |
1 | 这里列出所有获取单个节点的方法: |
1 | 另外,Selenium还提供了通用方法find_element(), 它需要传入两个参数:查找方式By和值。 |
多个节点
1 | 如果查找的目标在网页中只有一个,那么完全可以用find_elem ent()方法。但如果有多个节点,再用find_elem ent()方法查找,就只能得到第一个节点了。如果要查找所有满足条件的节点,需要用 |
1 | from selenium import webdriver |
1 | 也就是说,如果我们用find_element()方法,只能获取匹配的第一个节点,结果是WebElement类型。如果用 find_elements()方法,则结果是列表类型,列表中的每个节点是WebElement类型。 |
1 | 这里列出所有获取多个节点的方法: |
节点交互
1 | Selenium可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见 |
1 | from selenium import webdriver |
1 | 这里首先驱动浏览器打开淘宝,然后用find_element_by_id()方法获取输入框,然后用 send_keys()方法输入iPhone文字,等待一秒后用clear()方法清空输入框,再次调用send_keys()方法输入 iPad文字,之后再用find_element_by_class_name()方法获取搜索按钮,最后调用click()方法完成搜索动作。 |
动作链
1 | 在上面的实例中,一些交互动作都是针对某个节点执行的。比如,对于输入框,我们就调用它的输入文字和清空文字方法;对于按钮,就调用它的点击方法。其实,还有另外一些操作,它们没有特定的执行对象,比如鼠标拖曳、键盘按键等,这些动作用另一种方式来执行,那就是动作链。 |
1 | 更 多 的 动 作 链 操 作 可 以 参 考 官 方 文 档 : http://selenium-python.readthedocs.io/api.html#moduleselenium.webdriver.common.actionchainso |
执行JavaScript
1 | 对于某些操作,Selenium API并没有提供。比如,下拉进度条,它可以直接模拟运行JavaScript,此时使用execute_script()方法即可实现,代码如下: |
获取节点信息
1 | 前面说过,通过page_source属性可以获取网页的源代码,接着就可以使用解析库(如正则表达式、Beautiful Soup、pyquery等)来提取信息了。 |
获取属性
1 | 我们可以使用g et_attribute()方法来获取节点的属性,但是其前提是先选中这个节点,示例如下: |
获取文本值
1 | 每个WebElement节点都有text属性,直接调用这个属性就可以得到节点内部的文本信息,这相当于Beautiful Soup的get_text()方法、pyquery的text()方法,示例如下: |
获取id、位置、标签名和大小
1 | 另外,WebElement节点还有一些其他属性,比如id属性可以获取节点id, location属性可以获取该节点在页面中的相对位置, tag_name属性可以获取标签名称,size属性可以获取节点的大小,也就是宽高,这些属性有时候还是很有用的。 |
1 | from.selenium import webdriver |
切换Frame
1 | 我们知道网页中有一种节点叫作ifram e,也就是子 F ram e,相当于页面的子页面,它的结构和外 |
1 | import time |
1 | 这里还是以前面演示动作链操作的网页为实例,首先通过switch_to.frame()方法切换到子Frame |
延时等待
1 | 在Selenium中,get()方法会在网页框架加载结束后结束执行,此时如果获取page_source,可能并不是浏览器完全加载完成的页面,如果某些页面有额外的Ajax请求 ,我们在网页源代码中也不一定能成功获取到。所以,这里需要延时等待一定时间,确保节点已经加载出来。 |
隐式等待
1 | 当使用隐式等待执行测试的时候,如果Selenium没有在D0M中找到节点,将继续等待,超出设定时间后,则抛出找不到节点的异常。换句话说,当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间再查找DoM ,默认的时间是0。示例如下: |
显式等待
1 | 隐式等待的效果其实并没有那么好,因为我们只规定了一个固定时间,而页面的加载时间会受到网络条件的影响。 |
1 | 这里首先引入WebDriverWait这个对象,指定最长等待时间,然后调用它的until()方法,传入要等待条件expected_conditionso比如,这里传入了 presence_of_element_located这个条件,代表节点出现的意思,其碁数是节点的定位元组,也就是ID为q的节点搜索框。 |
1 | 这样可以做到的效果就是,在10秒内如果ID为q的节点(即搜索框)成功加载出来,就返回该节点;如果超过10秒还没有加载出来,就抛出异常。 |
1 | 关于等待条件,其实还有很多,比如判断标题内容,判断某个节点内是否出现了某文字等。 |
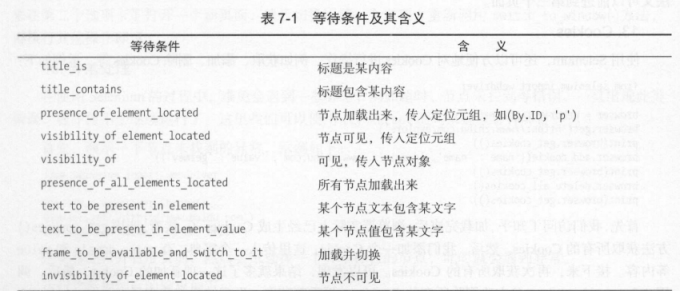

1 | 关于更多等待条件的参数及用法,可以参考官方文档: http://selenium-python.readthedocs.io/ |
前进和后退
1 | 平常使用浏览器时都有前进和后退功能, Selenium也可以完成这个操作,它使用back()方法后退, |
Cookies
1 | 使用Selenium,还可以方便地对Cookies进行操作,例如获取、添加、删除 Cookies等。示例如下: |
选项卡管理
1 | 在访问网页的时候,会开启一个个选项卡。在 Selenium中,我们也可以对选项卡进行操作。示例如下: |
异常处理
1 | 在使用Selenium的过程中,难免会遇到一些异常,例如超时、节点未找到等错误,一旦岀现此类错误,程序便不会继续运行了。这里我们可以使用try except语句来捕获各种异常。 |
1 | 可以看到,这里抛出了NoSuchElementException异常,这通常是节点未找到的异常。为了防止程序遇到异常而中断,我们需要捕获这些异常,示例如下: |
1 | 这里我们使用try except来捕获各类异常。比如,我们对find_element_by_id( )查找节点的方法捕获 NoSuchElementException异常,这样一旦出现这样的错误,就进行异常处理,程序也不会中断了。 |

