崔庆才python3爬虫-13章 Scrapy框架的使用-Spider Middleware的用法和Item Pipeline
Spider Middleware的用法
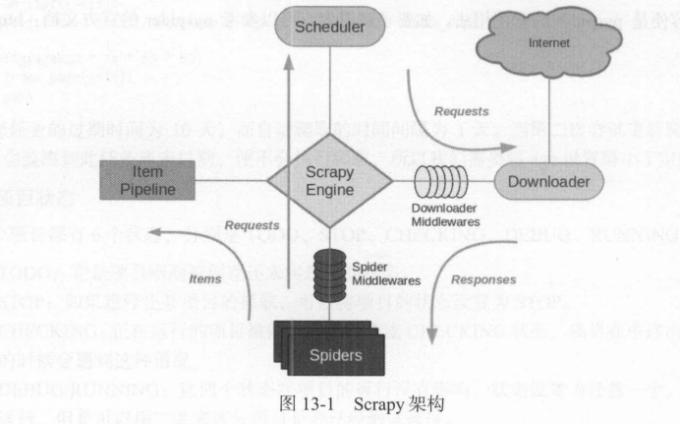
1 | Spider Middleware是介入到Scrapy的 Spider处理机制的钩子框架。我们首先来看看它的架构,如图13-1所示。 |
使用说明
1 | 需要说明的是,Scrapy其实已经提供了许多Spider Middleware, 它们被 SPIDER_MIDDLEWARES_BASE这个变量所定义。 |
核心方法
1 | Scrapy内置的Spider Middleware为Scrapy提供了基础的功能。如果我们想要扩展其功能,只需要实现某几个方法即可。 |
1 | 只需要实现其中一个方法就可以定义一个Spider Middlewareo 下面我们来看看这4 个方法的详细用法。 |
process_spider_input(response, spider)
1 | 当Response被Spider Middleware处理时,process_spider_input()方法被调用。 |
process_spider_output(response, result, spider)
1 | 当Spider处理Response返回结果时,process_spider_output()方法被调用。 |
process_spider_exception(response, exception, spider)
1 | 当Spider或Spider Middleware的process_spider_input()方法抛出异常时,process_spider_exception()方法被调用。 |
process_start_reqeusts(start.requests, spider)
1 | process_start_requests()方法以Spider启动的Request为参数被调用,执行的过程类似于process_spider_output(),只不过它没有相关联的Response,并且必须返回Request |
1 | 本节介绍了Spider Middleware 的基本原理和自定义Spider Middleware 的方法。 Spider Middleware |
Item Pipeline
1 | Item Pipeline是项目管道。在前面我们已经了解了Item Pipeline的基本用法,本节我们再作详细了解它的用法。 |
核心方法
1 | 我们可以自定义Item Pipeline,只需要实现指定的方法,其中必须要实现的一个方法是 : |
process_item(item, spider)
1 | process_item()是必须要实现的方法,被定义的Item Pipeline会默认调用这个方法对Item进行处理比如,我们可以进行数据处理或者将数据写入到数据库等操作。(它必须返回Item类型的值或者抛出一个Dropitem异常。) |
open_spider(self, spider)
1 | open_spider()方法是在Spider开启的时候被自动调用的。在这里我们可以做一些初始化操作,如开启数据库连接等。其中,参数spider就是被开启的Spider对象。 |
close_spider(spider)
1 | close_spider()方法是在Spider关闭的时候自动调用的。在这里我们可以做一些收尾工作,如关闭数据库连接等。其中,参数spider就是被关闭的Spider对象 |
from_crawler(cls, crawler)
1 | from_crawler()方法是一个类方法,用@classmethod标识,是一种依赖注入的方式。它的参数是crawler,通过crawler对象,我们可以拿到Scrapy的所有核心组件,如全局配置的每个信息,然后创建一个Pipeline实例。参数cls就是 Class,最后返回一个Class实例。 |
实战
1 | 我们以爬取360摄影美图为例,来分别实现MongoDB存储、MySQL存储、Image图片存储的三个Pipeline |
1 | 我们这次爬取的目标网站为:https://image.so.com。打开此页面,切换到摄影页面,网页中呈现了许许多多的摄影美图。我们打开浏览器开发者工具,过滤器切换到XHR选项,然后下拉页面,可以看到下面就会呈现许多Ajax请求 |
1 | 返回格式是JSON |
创建项目
1 | 首先新建一个项目,命令如下所示: |
构造请求
1 | 接下来定义爬取的页数。比如爬取50页、每页30张,也就是1500张图片,我们可以 |
提取信息
1 | 首先定义一个Item,叫作Imageltem,如下所示: |
1 | 接下来我们提取Spider里有关信息,将parse()方法改写为如下所示: |
存储信息
MONGODB
1 | 首先确保MongoDB已经正常安装并且正常运行。 |
1 | 这里需要用到两个变量,MONGO_URI和MONGO_DB,即存储到MongoDB的链接地址和数据库名称。 |
MySQL
1 | 首先确保MySQL已经正确安装并且正常运行。 |
1 | 接下来我们实现一个MySOLPipeline,代码如下所示: |
Image Pipeline
1 | Scrapy提 供了专门处理下载的Pipeline,包括文件下载和图片下载。下载文件和图片的原理与抓取页面的原理一样,因此下载过程支持异步和多线程,下载十分高效。下面我们来看看具体的实现过程。 |
1 | 首先定义存储文件的路径,需要定义一个IMAGES_STORE变量,在 settings.py中添加如下代码: |
1 | from scrapy import Request |
1 | 在这里我们实现了ImagePipeline,继承Scrapy内置的Im agesPipeline,重写下面几个方法。 |
1 | 现在为止,三个Item Pipeline的定义就完成了。最后只需要启用就可以了,修改settings.py, 设置ITEM_PIPELINES,如下所示: |
1 | 这里注意调用的顺序。我们需要优先调用ImagePipeline对Item做下载后的筛选,下载失败的Item就直接忽略,它们就不会保存到MongoDB和MySQL里。随后再调用其他两个存储的Pipeline,这样就能确保存入数据库的图片都是下载成功的。 |
没有伞的孩子,必须努力奔跑!
Typewriter Mode** 已开启。
可以在视图菜单中关闭
不再显示关闭

