崔庆才python3爬虫-13章 Scrapy框架的使用
Scrapy框架介绍
1. 架构介绍
1 | Scrapy是一个基于Twisted的异步处理框架,是 纯 Python实现的爬虫框架,其架构清晰,模块之间的耦合程度低,可扩展性极强,可以灵活完成各种需求。我们只需要定制开发几个模块就可以轻松实现一个爬虫。 |
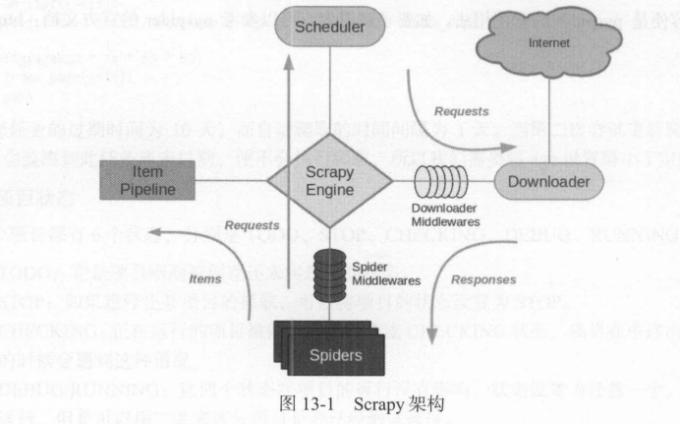
1 | 它可以分为如下的几个部分。 |
2. 数据流
1 | Scrapy中的数据流由引擎控制,数据流的过程如下。 |
3 . 项目结构
1 | scrapy.cfg |
1 | 这里各个文件的功能描述如下。 |
4 .结语
1 |
|
Scrapy 入门
Scrapy安装
创建项目
1 | 创 建 一 个 Scrapy项目,项目文件可以直接用scrapy命令生成,命令如下所示: |
1 | 这个命令将会创 |
创建Spider
1 | Spider是自己定义的类,Scrapy用它来从网页里抓取内容,并解析抓取的结果。不过这个类必须继承Scrapy提供的Spider类 scrapy.Spider,还要定义Spider的名称和起始请求,以及怎样处理爬取后的结果的方法。 |
1 | 这里有三个属性--- name、 allowed_domains和 start_ur ls ,还有一个方法parse。 |
创建Item
1 | Item是保存爬取数据的容器,它的使用方法和字典类似。不过,相比字典,Item多了额外的保护机制,可以避免拼写错误或者定义字段错误。 |
1 | import scrapy |
解析Response
1 | 前面我们看到, parse()方法的参数 resposne是start_urls里面的链接爬取后的结果。所以在parse()方法中,我们可以直接对response变量包含的内容进行解析,比如浏览请求结果的网页源代码,或者进一步分析源代码内容,或者找岀结果中的链接而得到下一个请求。 |
1 | 首先看看网页结构,如 图 13・2所示。每一页都有多个class为quote的区块,每个区块内都包含text、author、tags。 那么我们先找出所有的quote ,然后提取每一个quote中的内容。 |
1 | 这里首先利用选择器选取所有的quote,并将其赋值为quotes变量,然后利用for循环对每个quote遍历,解析每个quote的内容。 |
使用Item
1 | 上文定义了Item ,接下来就要使用它了。Item可以理解为一个字典,不过在声明的时候需要实例化。然后依次用刚才解析的结果赋值Item 的每一个字段,最后 将Item返回即可。 |
1 | 如此一来,首页的所有内容被解析出来,并被赋值成了一个个Quoteltem |
后续Request
1 | 上面的操作实现了从初始页面抓取内容。那么,下一页的内容该如何抓取?这就需要我们从当前页面中找到信息来生成下一个请求,然后在下一个请求的页面里找到信息再构造再下一个请求。 这样循环往复迭代,从而实现整站的爬取。 |
1 | 将刚才的页面拉到最底部,这里有一个Next按钮。查看它的源代码,可以发现它的链接是/page/2/,全链接就是: http://quotes.toscrape.com/page/2,通过这个链接我们就可以构造下一个请求 |
1 | 由于parse()就是解析text、author、tags的方法,而下一页的结构和刚才已经解析的页面结构是一样的,所以我们可以再次使用parse()方法来做页面解析。 |
1 | 第一句代码首先通过CSS选择器获取下一个页面的链接,即要获取a超链接中的href属性。这里用到了::attr(href)操作。然后再调用extract_first()方法获取内容。 |
1 | import scrapy |
运行
1 | 接下来,进入目录,运行如下命令: |
1 | 首先, Scrapy输出了当前的版本号以及正在启动的项目名称。接着输出了当前settings.py中一些重写后的配置。然后输出了当前所应用的Middlewares和 Pipelines。Middlewares默认是启用的,可以在settings.py中修改。 Pipelines默认是空,同样也可以在settings.py中配置。后面会对它们进行讲解。 |
保存到文件
1 | 运行完 Scrapy后 ,我们只在控制台看到了输出结果。如果想保存结果该怎么办呢? |
1 | 输出格式还支持很多种,例如csv、xml、pickle、marshal等,还支持 ftp、 s3等远程输出,另外还可以通过自定义ItemExporter来实现其他的输出。 |
1 | 通 过 Scrapy提供的Feed Exports,我们可以轻松地输出抓取结果到文件。对于一些小型项目来说, |
使用Item Pipeline
1 | 如果想进行更复杂的操作,如将结果保存到MongoDB数据库,或者筛选某些有用的Item ,则我们可以定义Item Pileline来实现。 |
1 | 要实现Item Pipeline很简单,只需要定义一个类并实现process_item()方法即可。启用Item Pipeline后,Item Pipeline会自动调用这个方法。 process_item()方法必须返回包含数据的字典或Item对象,或者抛出Dropltem异常。 |
1 | 修改项目里的pipelines.py文件,之前用命令行自动生成的文件内容可以删掉,增加一个TextPipeline类,内容如下所示: |
1 | 这段代码在构造方法里定义了限制长度为50, 实现了 process_item()方法,其参数是item和spider。首先该方法判断item 的text属性是否存在,如果不存在,则抛出Dmpltem异常;如果存在, |
1 | 接下来,我们将处理后的item存入MongoDB,定义另外一个Pipelineo同样在pipelines.py中, |
1 | MongoPipeline类实现了 API定义的另外几个方法。 |
1 | 赋值ITEM_PIPELINES字典,键名是Pipeline的类名称,键值是调用优先级,是一个数字,数字越小则对应的Pipeline越先被调用。 |
1 | 再重新执行爬取,命令如下所示: |
Item Adaptor
1 | ~~~ |
没有伞的孩子,必须努力奔跑!
Typewriter Mode** 已开启。
可以在视图菜单中关闭
不再显示关闭

