第六周 第二章 剖析数据倾向问题与企业级解决方案
1 | 在实际工作中,如果我们想提高MapReduce的执行效率,最直接的方法是什么呢? |
源码解析
1 | 那我们来看一下HashPartitioner的实现是什么样子的 |
1 | HashPartitioner继承了Partitioner,这里面其实就一个方法,getPartition,其实map里面每一条数据都会进入这个方法来获取他们所在的分区信息,这里的key就是k2,value就是v2 |
案例分析
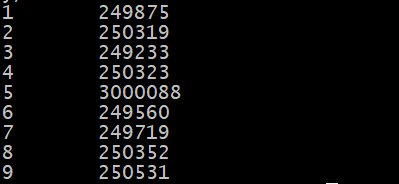
1 | 下面我们来分析一个场景: |
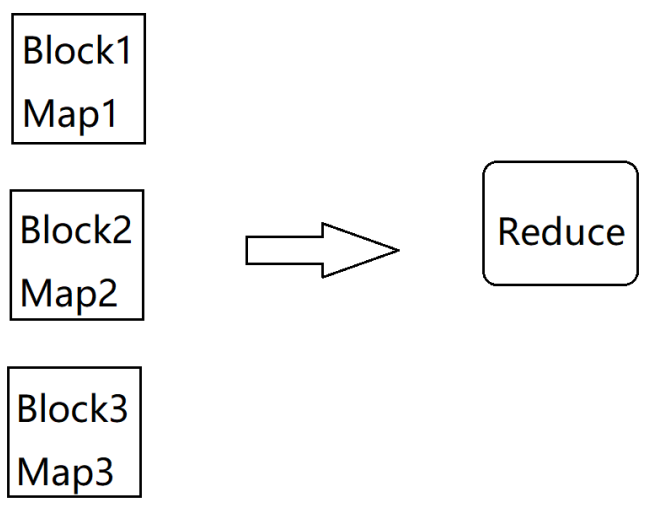
1 | 那根据我们前面的分析,我们可以增加reduce任务的数量,看下面这张图,我们把reduce任务的数量调 |
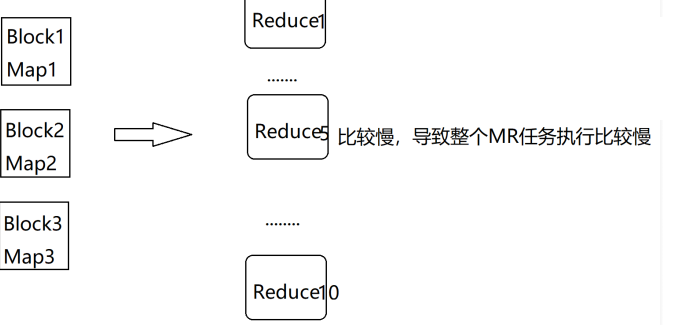
1 | 我们来分析一下,刚才我们说了我们这份数据中,值为5的数据有910w条,这就占了整份数据的90%了,那这90%的数据会被一个reduce任务处理,在这里假设是让reduce5处理了,reduce5这个任务执行的是比较慢的,其他reduce任务都执行结束很长时间了,它还没执行结束,因为reduce5中处理的数据量和其他reduce中处理的数据量规模相差太大了,所以最终reduce5拖了后腿。咱们mapreduce任务执行消耗的时间是一直统计到最后一个执行结束的reduce任务,所以就算其他reduce任务早都执行结束了也没有用,整个mapreduce任务是没有执行结束的。 |
案例实操
1 | 现在呢我们通过理论层面分析完了,那接下来我们来具体进入一个实际案例上手操作一下 |

1 | [root@bigdata01 soft]# tail -1 hello_10000000.dat |

1 | 接下来把这个文件上传到hdfs上 |
1 | 下面我们来具体跑一个这份数据,首先复制一份WordCountJob的代码,新的类名为 WordCountJobSkew |
1 | package com.imooc.mr; |
1 |
|
1 | /** |
1 | 对项目代码进行重新编译、打包,提交到集群去执行 |





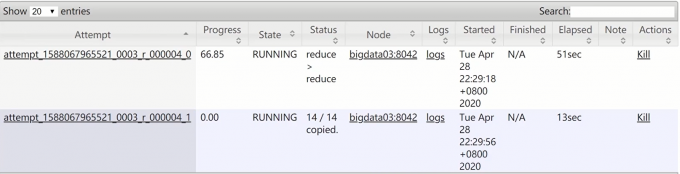
1 | kill有两个的原因是:当一个某一map任务执行很慢时,会再启动一个map任务去计算同一份数据,其中一个计算执行完成后,会kill掉未执行完那个(map推测执行) |

1 | 查看结果 |


1 | 接下来增加reduce任务的数量,增加到10个 |

1 | 这里的这两个reduce任务也是推测执行,处理的同一份数据 |
1 | 推测执行可以关掉 |



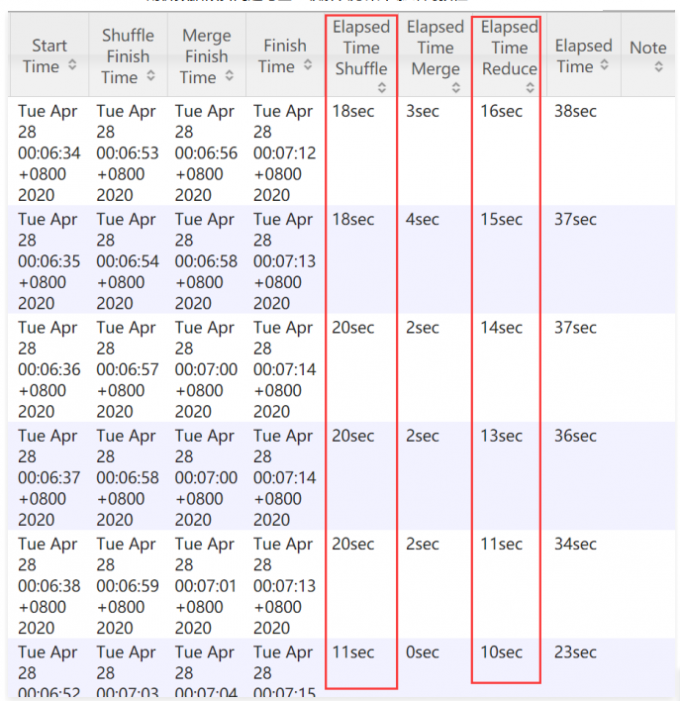
1 | 这里显示比第一次1个reduce任务的执行时间还长,虽然和机器当前状态有关,但至少得出这种情况下(数据倾斜)单纯加大reduce任务数量,并不会产生明显的速度提升 |
把倾斜数据打散
1 | 怎么打散呢?其实就是给他加上一些有规律的随机数字就可以了 |
1 | package com.imooc.mr; |
1 | 只需要在map中把k2的值修改一下就可以了,这样就可以把值为5的数据打散了。 |
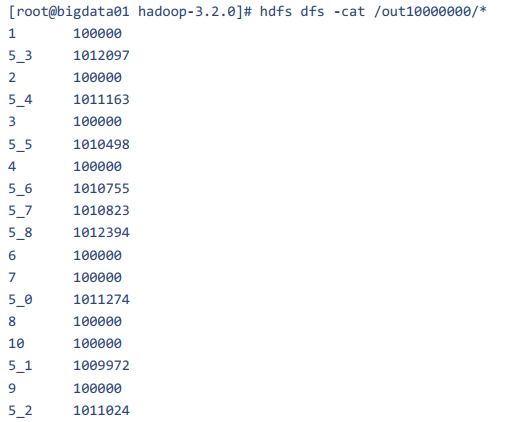
1 | 注意,这个时候获取到的并不是最终的结果,因为我们把值为5的数据随机分成多份了,最多分成10份 |

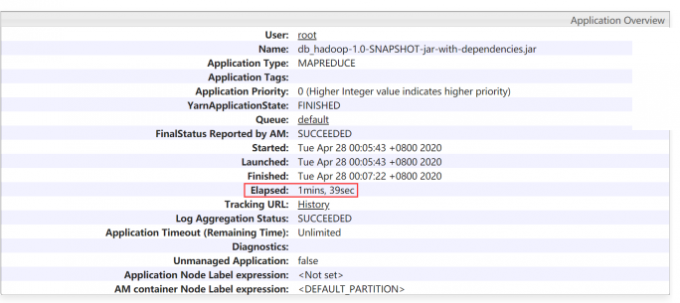
1 | 任务总的执行消耗时间为: Elapsed: 1mins, 39sec |

1 | 但是这个时候我们获取到的最终结果是一个半成品,还需要进行一次加工,其实我们前面把这个倾斜的数据打散之后相当于做了一个局部聚合,现在还需要再开发一个mapreduce任务再做一次全局聚合,其实也很简单,获取到上一个map任务的输出,在map端读取到数据之后,对数据先使用空格分割,然后对第一列的数据再使用下划线分割,分割之后总是取第一列,这样就可以把值为5的数据还原出来了,这个时候数据一共就这么十几条,怎么处理都很快了,这个代码就给大家留成作业了,我们刚才已经把详细的过程都分析过了,大家下去之后自己写一下,如果遇到了问题,可以在咱们的问答区一块讨论,或者直接找我都是可以的。 |
编写代码
1 | 主要设置: |
自己创建的测试数据
1 | 一共5000000行 |
map
1 | protected void map(LongWritable k1, Text v1, Context context) |
reduce
1 | public static class myReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ |
main
1 | public static void main(String[] args){ |
结果查看

1个reduceTask
1 | hadoop jar bigdata_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mc.WordCountJobSkew /test/shujuqingxie/QingXieData.txt /test/shujuqingxie/outcome1 1 |

1 | 具体分析页面打不开 |
9个reduceTask
1 | hadoop jar bigdata_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mc.WordCountJobSkew /test/shujuqingxie/QingXieData.txt /test/shujuqingxie/outcome1 9 |
分析
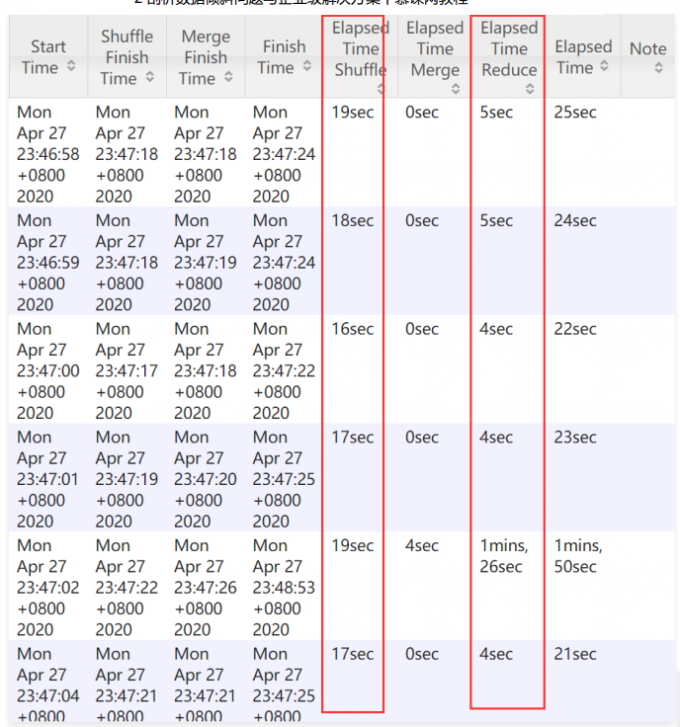
1 | 所以从这可以看出来,性能提升并不大 |

1 | map任务14个里面,kill 2个是因为“推测执行”,当map任务里某些maptask任务相比其它maptask明显慢很多时(会认为是有异常),会自动产生新的maptask任务,两个一起执行,最后杀掉慢的 下面这是reduce阶段某个reducetask的推测执行 |
把倾斜的数据打散(面试)
1 | 那我们再把reduce任务的个数提高一下,会不会提高性能呢?不会了,刚才从1个reduce任务提高到10个reduce任务时间也就减少了三四秒钟,所以再增加reduce任务的个数就没有多大意义了。 |
map
1 | 只需要在map中把k2的值修改一下就可以了,这样就可以把值为5的数据打散了。 |
reduce
1 | 没变 |
分析
1 | 注意,这个时候获取到的并不是最终的结果,因为我们把值为5的数据随机分成多份了,最多分成10份 |
1 | 但是这个时候我们获取到的最终结果是一个半成品,还需要进行一次加工,其实我们前面把这个倾斜的数据打散之后相当于做了一个局部聚合,现在还需要再开发一个mapreduce任务再做一次全局聚合,其实也很简单,获取到上一个map任务的输出,在map端读取到数据之后,对数据先使用空格分割,然后对第一列的数据再使用下划线分割,分割之后总是取第一列,这样就可以把值为5的数据还原出来了,这个时候数据一共就这么十几条,怎么处理都很快了,这个代码就给大家留成作业了,我们刚才已经把详细的过程都分析过了,大家下去之后自己写一下,如果遇到了问题,可以在咱们的问答区一块讨论,或者直接找我都是可以的。 |