第六周 第三章 YARN实战
HADOOP之YARN详解
1 | 前面我们学习了Hadoop中的MapReduce,我们知道MapReduce任务是需要在YARN中执行的,那下面我们就来学习一下Hadoop中的YARN |
YARN的由来
1 | 从Hadoop2开始,官方把资源管理单独剥离出来,主要是为了考虑后期作为一个公共的资源管理平台,任何满足规则的计算引擎都可以在它上面执行。 |
YARN架构分析
1 | 咱们之前部署Hadoop集群的时候也对YARN的架构有了基本的了解 |
YARN资源管理模型
1 | YARN主要管理内存和CPU这两种资源类型 |


1 | 那我们再详细看一下每一个从节点的资源信息 |
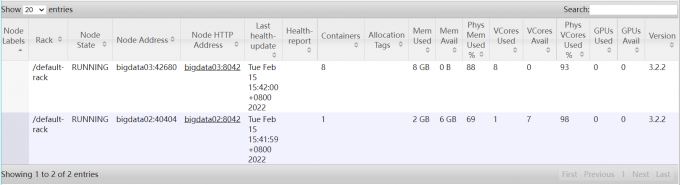


1 | 但是这个数值是对不上的,我的linux机器每台只给它分配了2G的内存 通过free -m可以看到 |

1 | 那为什么在这里显示是内存是8G,CPU是8个呢? |
YARN中的调度器(面试中经常问)
1 | 接下来我们来详细分析一下YARN中的调度器,这个是非常实用的东西,面试的时候也会经常问到。 |
1 | 具体如何去做这个是由YARN中的调度器负责的 |
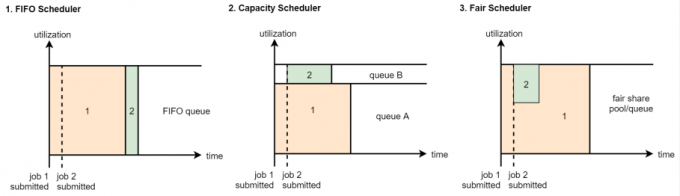
1 | FIFO Scheduler:是先进先出的,大家都是排队的,如果你的任务申请不到足够的资源,那你就等着,等前面的任务执行结束释放了资源之后你再执行。这种在有些时候是不合理的,因为我们有一些任务的优先级比较高,我们希望任务提交上去立刻就开始执行,这个就实现不了了。 |
1 | 在实际工作中我们一般都是使用第二种,CapacityScheduler,从hadoop2开始,Capacity Scheduler也是集群中的默认调度器了 |
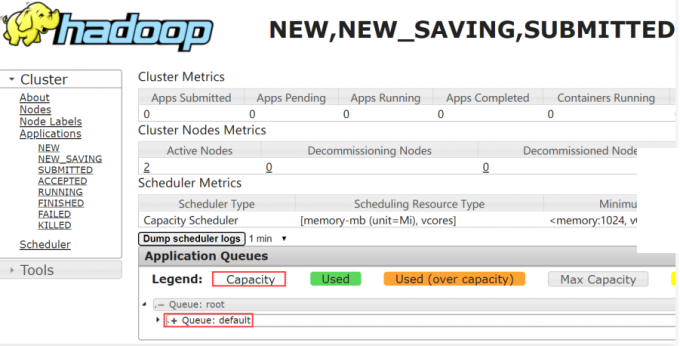
1 | Capacity,这个是集群的调度器类型, |
案例:YARN多资源队列配置和使用
配置
1 | 下面我们来修改一下,增加多个队列 |
1 | 我们的需求是这样的,希望增加2个队列,一个是online队列,一个是offline队列 |
1 | <property> |
1 | 资源上限可以基于上面设置的比例上调,如default的上限设置成80,则它去抢占其它队列的资源 |
1 | 修改好以后再同步到另外两个节点上 |

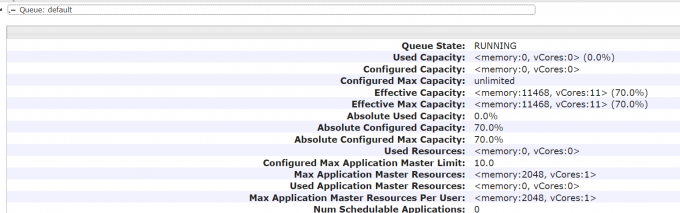
使用
1 | 注意了,现在默认提交的任务还是会进入default的队列,如果希望向offline队列提交任务的话,需要指定队列名称,不指定就进默认的队列 |
代码的改变
1 | 在最初的wordcount案例代码基础上 |
1 | // 指定Job需要的配置参数 |
1 | 如果真正理解了的话可以直接在代码里写,不用通过命令传 |
打包,上传,执行
1 | hadoop jar bigdata_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mc.WordCountJobQueue -Dmapreduce.job.queuename=offline /test/WordCount/test/test.txt /test/WordCount/test/outcomeScheduler |

1 | 如果我们去掉指定队列名称的配置(命令中,代码不用改),此时还会使用default队列 |

