第八周 第1章 快速了解Hive
什么是Hive
1 | Hive是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载,可以简称为ETL。 |
Hive的数据存储
1 | Hive的数据存储基于Hadoop的HDFS |
Hive的系统架构
1 | 下面我们来分析一下Hive的系统架构 |
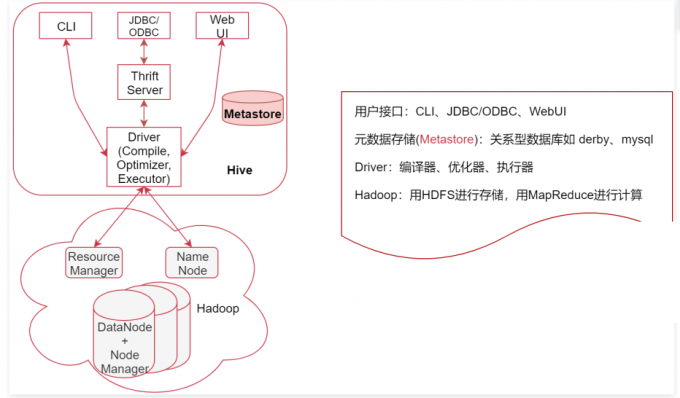
1 | 用户接口,包括 CLI、JDBC/ODBC、WebGUI |
1 | 元数据存储(Metastore),注意:这里的存储是名词,Metastore表示是一个存储系统 |
1 | Driver:包含:编译器、优化器、执行器 |
1 | Hadoop:Hive会使用HDFS 进行存储,利用MapReduce进行计算 |
1 | 在这有一点需要注意的,就是从Hive2开始,其实官方就不建议默认使用MapReduce引擎了,而是建议使用Tez引擎或者是Spark引擎,不过目前一直到最新的3.x版本中mapreduce还是默认的执行引擎 |
1 | 所以发现没有,MapReduce、Tez、Spark、Flink这些计算引擎都是支持在yarn上执行的,所以说Hdoop2中对架构的拆分是非常明智的。 |
Metastore
1 | 接着来看一下Hive中的元数据存储 |

