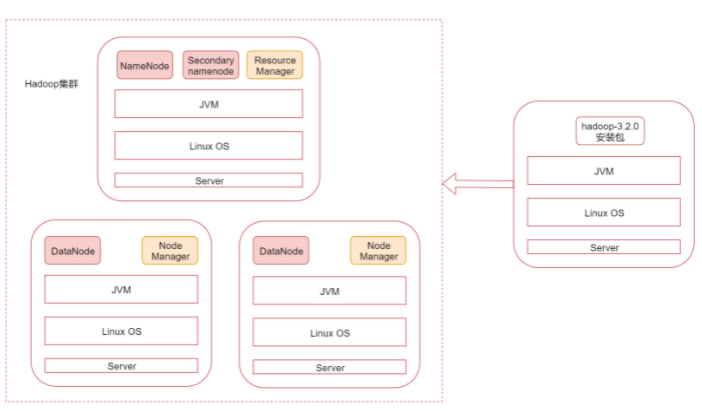
第二周 大数据起源之初识Hadoop
第一章初识Hadoop
什么是Hadoop
1 | Hadoop是一个适合海量数据的分布式存储和分布式计算的框架。 |
Hadoop发行版介绍
1 | 在这里我们挑几个重点的分析一下: |
1 | 在这里我们会学习原生的Hadoop,只要掌握了原生Hadoop使用,后期想要操作其它发行版的Hadoop也是很简单的,其它发行版都是会兼容原生Hadoop的,这一点大家不同担心。 原生Hadoop的缺点是没有技术支持,遇到问题需要自己解决,或者通过官网的社区提问,但是回复一般比较慢,也不保证能解决问题, 还有一点就是原生Hadoop搭建集群的时候比较麻烦,需要修改很多配置文件,如果集群机器过多的话,针对运维人员的压力是比较大的,这块等后面我们自己在搭建集群的时候大家就可以感受到了。 |
1 | 最终的建议:建议在实际工作中搭建大数据平台时选择CDH或者HDP,方便运维管理,要不然,管理上千台机器的原生Hadoop集群,运维同学是会哭的。 |
Hadoop版本演变历史
1 | hadoop1.x:HDFS+MapReduce |

1 | 在Hadoop1.x中,分布式计算和资源管理都是MapReduce负责的,从Hadoop2.x开始把资源管理单独拆分出来了,拆分出来的好处就是,YARN变成了一个公共的资源管理平台,在它上面不仅仅可以跑MapReduce程序,还可以跑很多其他的程序,只要你的程序满足YARN的规则即可 |
Hadoop3.x的细节优化
1 | 在这里我挑几个常见点说一下: |
Hadoop三大核心组件介绍
1 | HDFS负责海量数据的分布式存储 |
第二章Hadoop的两种安装方式
伪分布集群安装
文章标题(可选)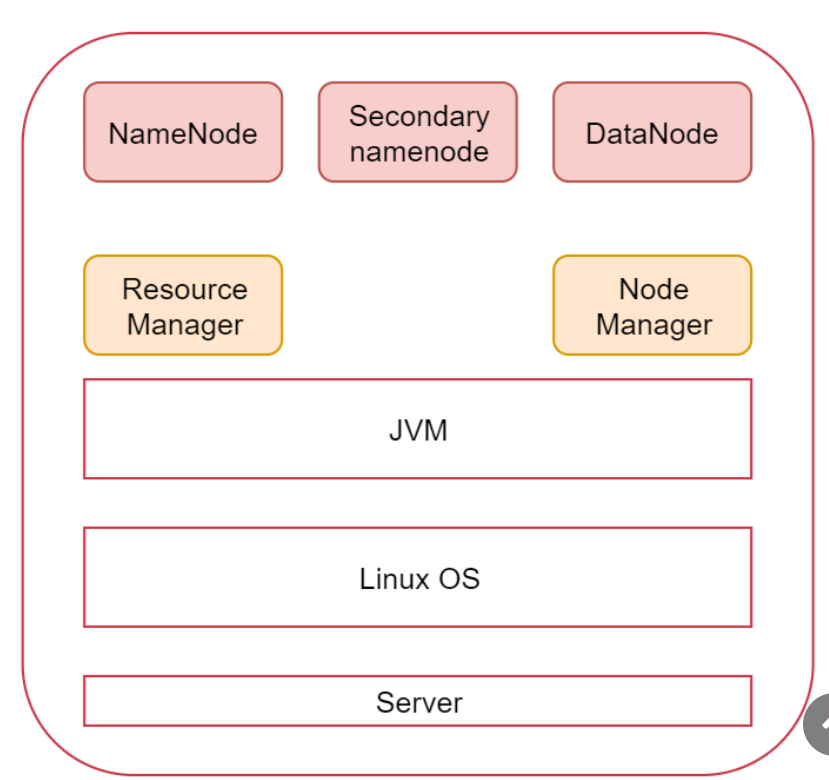
1 | 伪分布集群部署:仅需要一台虚拟机 |
配置基础环境
设置静态ip
1 | /etc/sysconfig/network-scripts/ifcfg-ens33 |

设置临时和永久hostname
1 | hostname xxx |
关闭firewalld
1 | systemctl stop firewalld 临时关闭 |
ssh免密码登录
我们下面要讲的hadoop集群就会使用到ssh,我们在启动集群的时候只需要在一台机器上启动就行,然后hadoop会通过ssh连到其它机器,把其它机器上面对应的程序也启动起来。但是现在有一个问题,就是我们使用ssh连接其它机器的时候会发现需要输入密码,所以现在需要实现ssh免密码登录。
1 | 那有同学可能有疑问了,你这里说的多台机器需要配置免密码登录,但是我们现在是伪分布集群啊,只有一台机器 |
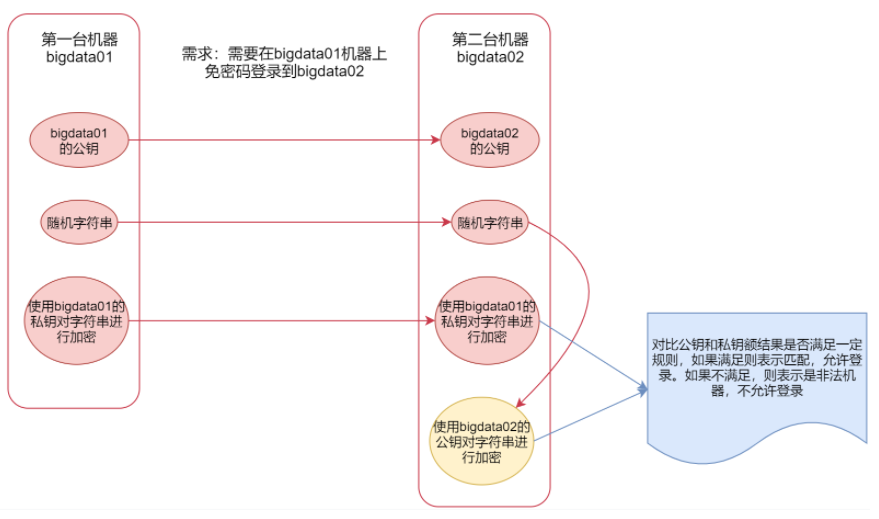
1 | 下面详细讲一下ssh免密码登录 ssh这种安全/加密的shell,使用的是非对称加密,加密有两种,对称加密和非对称加密。非对称加密的解密过程是不可逆的,所以这种加密方式比较安全。 |
1 | 下面就开始正式配置一下ssh免密码登录,由于我们这里要配置自己免密码登录自己,所以第一台机器和第二台机器都是同一台 |
JDK安装
1 | 略 |
hadoop安装
1 | 1.将文件解压到创建的/data/soft/下 |
1 | 3:修改Hadoop相关配置文件 |
1 | 首先修改 hadoop-env.sh 文件,增加环境变量信息,添加到hadoop-env.sh文件末尾即可。 |
1 | 修改core-site.xml文件 |
1 | 修改hdfs-site.xml文件,把hdfs中文件副本的数量设置为1,因为现在伪分布集群只有一个节点 |
1 | 修改mapred-site.xml,设置mapreduce使用的资源调度框架 |
1 | 修改yarn-site.xml,设置yarn上支持运行的服务和环境变量白名单 |
1 | 修改workers,设置集群中从节点的主机名信息,在这里就一台集群,所以就填写bigdata01即可 |
1 | 配置文件到这就修改好了,但是还不能直接启动,因为Hadoop中的HDFS是一个分布式的文件系统,文件系统在使用之前是需要先格式化的,就类似我们买一块新的磁盘,在安装系统之前需要先格式化才可以使用。 |
1 | 5:启动伪分布集群 |
1 | 执行的时候发现有很多ERROR信息,提示缺少HDFS和YARN的一些用户信息。 |
1 | 修改sbin目录下的start-yarn.sh,stop-yarn.sh这两个脚本文件,在文件前面增加如下内容 |
1 | 再启动集群 |
1 | 7:停止集群 |
分布式集群安装
1 | 伪分布集群搞定了以后我们来看一下真正的分布式集群是什么样的 |
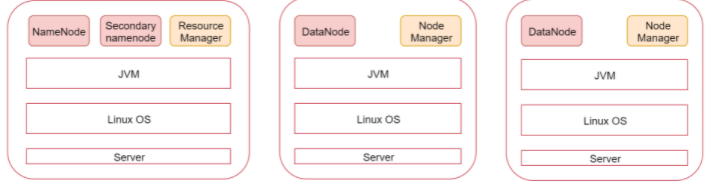
1 | 下面我们就根据图中的规划实现一个一主两从的hadoop集群 |
1 | 这些基础环境配置好以后还没完,还有一些配置需要完善。 |
1 | 集群节点之间时间同步 |
1 | 然后手动执行ntpdate -u ntp.sjtu.edu.cn 确认是否可以正常执行 |
1 | SSH免密码登录完善 |
1 | 有没有必要实现从节点之间互相免密码登录呢? |
1 | 修改core-site.xml文件,注意fs.defaultFS属性中的主机名需要和主节点的主机名保持一致 |
1 | 修改hdfs-site.xml文件,把hdfs中文件副本的数量设置为2,最多为2,因为现在集群中有两个从节点,还有secondaryNamenode进程所在的节点信息 |
1 | 修改mapred-site.xml,设置mapreduce使用的资源调度框架 |
1 | 修改yarn-site.xml,设置yarn上支持运行的服务和环境变量白名单 |
1 | 修改workers文件,增加所有从节点的主机名,一个一行 |
1 | 修改启动脚本 |
1 | 修改start-yarn.sh,stop-yarn.sh这两个脚本文件,在文件前面(一定要注意位置,license后面)增加如下内容 |
1 | 4:把bigdata01节点上将修改好配置的安装包拷贝到其他两个从节点 |
1 | 6:启动集群,在bigdata01节点上执行下面命令 |
1 | 7:验证集群 |
Hadoop的客户端节点
1 | 在实际工作中不建议直接连接集群中的节点来操作集群,直接把集群中的节点暴露给普通开发人员是不安全的 |