第九周 第2章 Scala基础语法
Scala的基本使用
变量
1 | scala中的变量分为两种:可变var和不可变val |
1 | scala> var a = 1 |
1 | 注意:在实际工作中,针对一些不需要改变值的变量,通常建议使用val,这样可以不用担心值被错误的修改(等于java中的final类型)。这样可以提高系统的稳定性和健壮性! |
数据类型
1 | Scala中的数据类型可以分为两种,基本数据类型和增强版数据类型 |
1 | scala> 1.to(10) |
1 | 使用基本数据类型,直接就可以调用RichInt中对应的函数 |
操作符
1 | Scala的算术操作符与Java的算术操作符没有什么区别 |
if 表达式
1 | 在Scala中,if表达式是有返回值的,就是if或者else中最后一行语句返回的值,这一点和java中的if是不一样的,java中的if表达式是没有返回值的 |
1 | 在这因为if表达式是有返回值的,所以可以将if表达式赋予一个变量 |
1 | 由于if表达式是有值的,而if和else子句的值的类型可能还不一样,此时if表达式的值是什么类型呢? |
1 | scala> if(age > 18) 1 else 0 |
1 | 如果if后面没有跟else,则默认else的值是Unit,也可以用()表示,类似于java中的void或者null |
1 | 如果想在scala REPL中执行多行代码,该如何操作? |
1 | scala> :paste |
语句终结符
1 | Scala默认不需要语句终结符,它将每一行作为一个语句 |
循环
print和println
1 | 在讲循环之前,先来看一下打印命令print和println |
for循环
1 | for循环本身的特性就没什么好说的了,直接上案例,主要注意一下scala中的for和java中的for在语法层面的区别 |
1 | scala> :paste |
1 | 这里面的to可以换成until |
1 | 对比两次执行的结果发现 |
1 | for循环针对字符串还可以用 |
1 | 注意:在这里我在for循环后面没有使用花括号,都省略了,主要是因为for循环的循环体代码就只有一行,如果有多行,就需要使用花括号了,否则,最终执行的结果就不是我们想要的 |
while循环
1 | while循环,它的用法和java中的while也是很像的,主要看一下语法层面的区别 |
高级for循环
if守卫模式
1 | 最后来看一下高级for循环的用法 |
1 | scala> for(i <- 1 to 10 if i % 2 == 0) println(i) |
for推导式
1 | for推导式,一个典型例子是构造集合 |
Scala的集合体系
1 | 接下来整体学习一下Scala中的集合体系,集合在工作中属于经常使用的数据结构 |
集合体系
1 | 首先看一下整个集合体系结构,这个结构与Java的集合体系非常相似 |
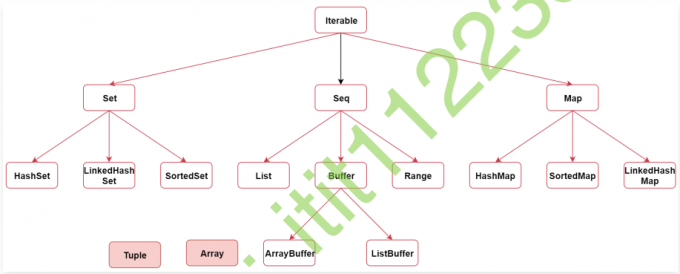
1 | 集合的顶层接口是Iterable,Iterable接口下面还有一些子接口, Set、Seq、Map |
集合
1 | Scala中的集合是分成可变和不可变两类集合的 |
1 | 先来看一下Set,Set代表一个没有重复元素的集合 |
Set
不可变set
1 | 这是不是很奇怪,本来Set是一个接口,但是却可以创建对象,更神奇的是竟然还不需要使用new关键字,这就有点颠覆我们的认知了 |
1 | 来看一下Scala的文档,你会发现这个Set不仅仅是一个接口,它还是一个Object,具体这个Object类型我 |
1 | 在这大家可以这样理解,只要前面带有object的,可以直接创建对象,并且不需要使用new关键字 |


1 | 注意:默认情况下直接创建的set集合是一个不可变集合,在这可以看到是在immutable包里面的,不可变集合中的元素一经初始化,就不能改变了,所以初始化后再向里面添加元素就报错了 |
1 | 但是注意,我使用s + 4 这种操作是可以的 |
1 | 这样是不是和我们刚才说的自相矛盾? |
可变set
1 | 如果想要创建一个可变的set集合,可以使用mutable包下面的set集合,显式指定包名 |
子类HashSet

1 | HashSet:这个集合的特点是:集合中的元素不重复、无序 |
1 | scala> val s = new scala.collection.mutable.HashSet[Int]() |
子类LinkedHashSet

1 | LinkedHashSet:这个集合的特点是:集合中的元素不重复、有序,它会用一个链表维护插入顺序,可以保证集合中元素是有序的 |
1 | LinkedHashSet只有可变的,没有不可变的 |
子类SortedSet
1 | SortedSet:这个集合的特点是:集合中的元素不重复、有序,它会自动根据元素来进行排序 |
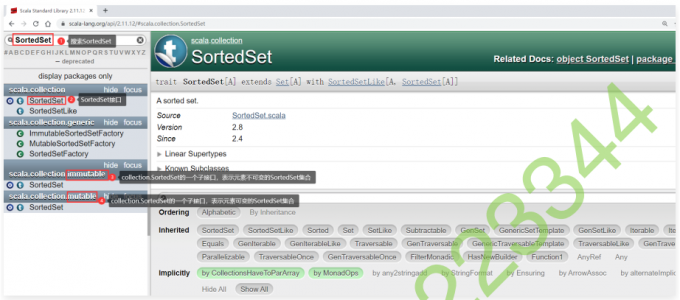
1 | 下面的那两个SortedSet是上面collection.SortedSet接口的子接口,一般会使用下面那两个。 |
1 | 从这可以看出来SortedSet集合中的元素是按照元素的字典顺序排序的 |
1 | 如果还有其它需求的话可以到这里来看一下文档 |

Sequence
List

1 | 接下来看一下List,List属于Seq接口的子接口 |
1 | 创建一个list |
1 | 注意:为什么有的地方需要写类的全路径,而有的不需要呢? |
head和tail
1 | 针对List有 head 、 tail 以及 :: 这几个操作 |
1 | head:表示获取List中的第一个元素 |
: :
1 | 通过 :: 操作符,可以将head和tail的结果合并成一个List |
1 | :: 这种操作符要清楚,在spark源码中是有体现的,一定要能够看懂 |
ListBuffer
1 | 在这里List是不可变的列表,在实际工作中使用的时候会很不方便,因为我们很多场景下都是需要向列表中动态添加元素,这个时候该怎么办呢? |
1 | scala> val lb = scala.collection.mutable.ListBuffer[Int]() |
Map
1 | Map是一种可迭代的键值对(key/value)结构 |
不可变Map
1 | 创建一个不可变的Map |
可变Map
1 | 创建一个可变的Map |
查询操作
1 | 1.获取指定key对应的value,如果key不存在,会报错 |
1 | 所以在实际工作中这样直接获取不太好,如果遇到了不存在的key程序会报错,导致程序异常退出。 |
1 | 这样是没问题的,就是写起来有点麻烦了,有没有方便一点的用法呢? |
修改
1 | 1.更新map中的元素(首先确保创建时使用的是mutable) |
1 | 2.增加多个元素 |
1 | 3.移除元素 |
遍历
1 | 1.遍历map的entrySet |
1 | 2.遍历map的key |
1 | 3.遍历map的value |
子类HashMap
1 | HashMap:是一个按照key的hash值进行排列存储的map |
子类SortedMap
1 | SortedMap:可以自动对Map中的key进行排序【有序的map】 |
1 | 在这主要演示一下SortedMap和LinkedHashMap |
子类LinkedHashMap
1 | LinkedHashMap:可以记住插入的key-value的顺序 |
1 | scala> val ages = new scala.collection.mutable.LinkedHashMap[String, Int]() |
Array
1 | Scala中Array的含义与Java中的数组类似,长度不可变 |
1 | scala> val a = new Array[Int](10) |
1 | 也可以直接使用Array()创建数组,元素类型自动推断 |
ArrayBuffer
1 | 如果想使用一个长度可变的数组,就需要使用到ArrayBuffer了 |
1 | 使用ArrayBuffer()的方式可以创建一个空的ArrayBuffer |
添加元素
1 | 1.使用+=操作符,可以添加一个元素,或者多个元素 |
移除元素
1 | 使用 remove() 函数可以移除指定位置的元素 |
Array和ArrayBuffer转化
1 | b.toArray:ArrayBuffer转Array |
数组常见操作
1 | 下面看一下针对数据的常见操作 |
遍历
1 | 1.scala> for(i <- b) println(i) |
求和,最大值
1 | scala> val sum = a.sum |
排序
1 | scala> scala.util.Sorting.quickSort(a) |
Tuple
1 | Tuple:称之为元组,它与Array类似,都是不可变的,但与数组不同的是元组可以包含不同类型的元素 |
1 | scala> val t = (1, 3.14, "hehe") |
总结
1 | 前面讲了很多集合体系中的数据结构,有的是可变的,有的是不可变的,有的是既是可变的又是不可变的,听起来有点乱,在这里我们总结一下 |
Scala中函数的使用
函数的定义
1 | 先来看一下函数的定义 |
1 | 单行函数 |
1 | 多行函数 |
函数的参数
默认参数
1 | 在Scala中,有时候我们调用某些函数时,不希望给出参数的具体值,而是希望使用参数自身默认的值,此时就需要在定义函数时使用默认参数。 |
1 | scala> def sayHello(fName: String, mName: String = "mid", lName: String = "la |
带名参数
1 | 在调用函数时,也可以不按照函数定义的参数顺序来传递参数,而是使用带名参数的方式来传递。 |
可变参数
1 | 在Scala中,有时我们需要将函数定义为参数个数可变的形式,则此时可以使用变长参数来定义函数 |
1 | scala> :paste |
特殊的函数-过程
1 | 在Scala中,定义函数时,如果函数体直接在花括号里面而没有使用=连接,则函数的返回值类型就是Unit,这样的函数称之为过程 |
1 | 有返回值 |
lazy
1 | Scala提供了lazy特性,如果将一个变量声明为lazy,则只有在第一次使用该变量时,变量对应的表达式才会发生计算 |
1 | scala> import scala.io.Source._ |
用法积累
1 | 1.字符串不能用单引号代替双引号 |

