第三周-Hadoop之HDFS的使用
第1章 HDFS介绍
假设让我们来设计一个分布式的文件系统,我们该如何设计呢?
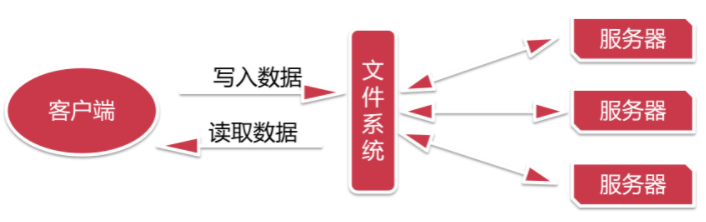
1 | 这种设计架构会存在一个问题,假设同时过来很多人都需要租房子,那么一个二房东是忙不过来的,就会造成阻塞。 |
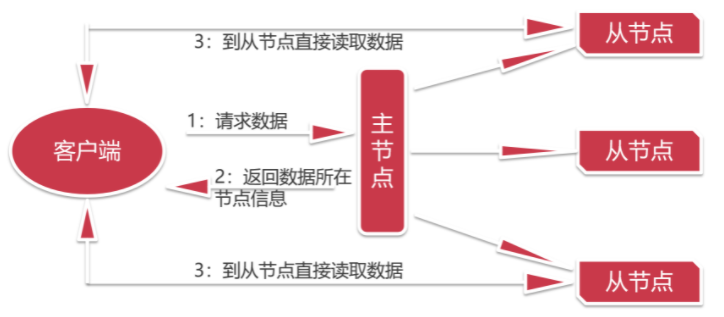
1 | 现在这种设计是,我们去找一个中介公司,这里的主节点就可以理解为一个中介公司 |
HDFS设计思想
1 | 用户请求查看数据时候会请求主节点,主节点上面会维护所有数据的存储信息,主节点会把对应数据所在的节点信息返回给用户,然后用户根据数据所在的节点信息去对应的节点去读取数据,这样压力就不会全部在主节点上面。 |
HDFS(Hadoop Distributed File System)
1 | Hadoop的 分布式文件系统 |
HDFS的Shell介绍
1 | 针对HDFS,我们可以在shell命令行下进行操作,就类似于我们操作linux中的文件系统一样,但是具体命令的操作格式是有一些区别的 格式如下: |
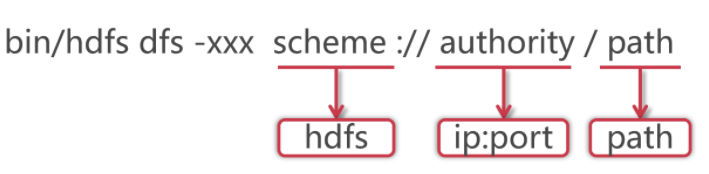
1 | 使用hadoop bin目录的hdfs命令,后面指定dfs,表示是操作分布式文件系统的,这些属于固定格式。 |
第2章 HDFS基础操作
HDFS的常见Shell操作
管理命令
操作命令
1 | 1.-ls [-R]:查询指定路径信息 |
1 | 2.-put:从本地上传文件 |
1 | 3.-cat:查看HDFS文件内容 |
1 | 5.-mkdir [-p]:创建文件夹 |
1 | 6.-rm [-r]:删除文件/文件夹 |
HDFS案例实操
1 | 需求:统计HDFS中文件的个数和每个文件的大小 |
第3章 java操作HDFS
Java代码操作HDFS
1 | 前面我们学习了在shell命令行下操作hdfs,shell中操作hdfs是比较常见的操作,但是在工作中也会遇到一些需求是需要通过代码操作hdfs的,下面我们就来看一下如何使用java代码操作hdfs |
1 | package com.imooc.hdfs; |
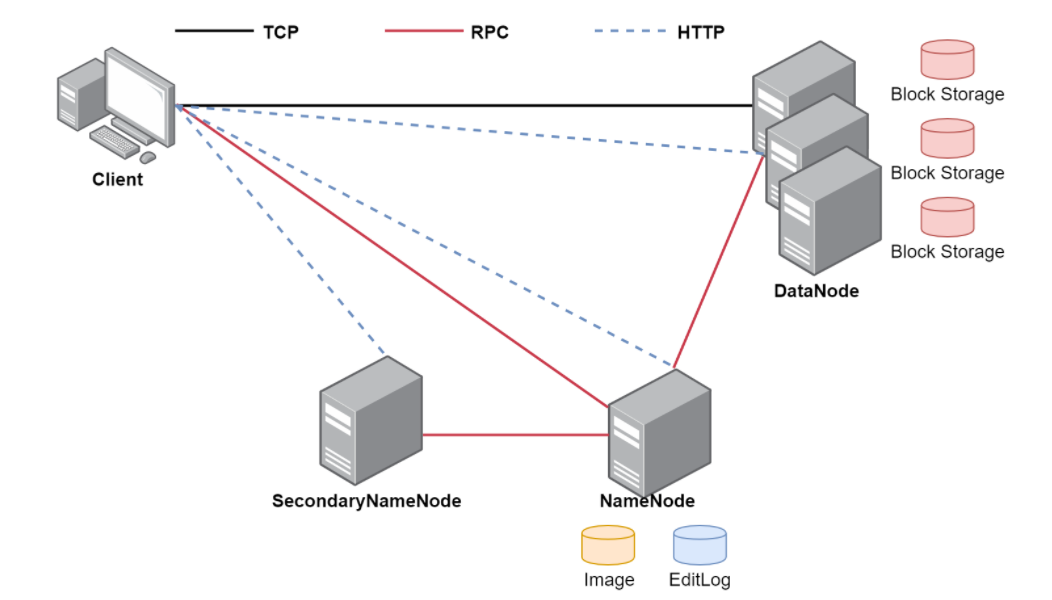
HDFS体系结构
1 | 前面我们掌握了HDFS的基本使用,下面我们来详细分析一下HDFS深层次的内容 |