第七周 第2章 极速上手Flume使用 采集网络日志上传到HDFS
1 | 前面我们讲了两个案例的使用,接下来看一个稍微复杂一点的案例: |
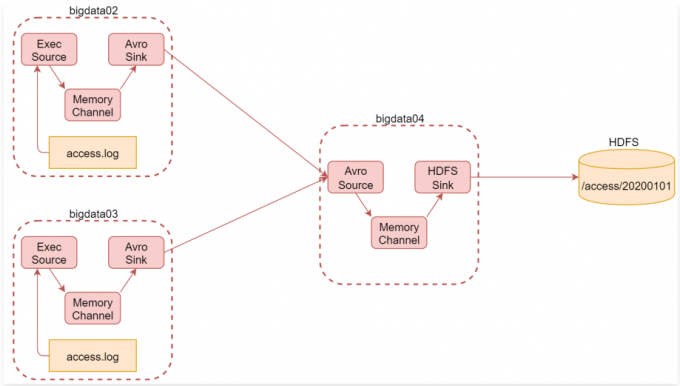
1 | 根据刚才的需求分析可知,我们一共需要三台机器 |
配置环境
bigdata02
1 | 1:在bigdata02上安装Flume并配置Agent |

1 | 配置Agent,创建文件 file-to-avro-101.conf |
bigdata03
1 | 2:在bigdata03上安装Flume并配置Agent |

1 | 配置Agent,创建文件file-to-avro-102.conf |
配置文件
1 | 注意:bigdata02和bigdata03中配置的a1.sinks.k1.port 的值45454需要和bigdata04中配置的一致 |
bigdata02 conf






1 | [root@bigdata02 conf]# vim file-to-avro-101.conf |
bigdata03 conf
1 | [root@bigdata03 conf]# vim file-to-avro-102.conf |
bigdata04 conf
1 | 这台机器我们已经安装过Flume了,所以直接配置Agent即可 |
1 | 那如何向header中添加日期呢? 其实官方文档中也说了,可以使用hdfs.useLocalTimeStamp或者时间拦截器,时间拦截器我们后面会讲,暂时最简单直接的方式就是使用hdfs.useLocalTimeStamp,这个属性的值默认为false,需要改为true。 |

1 | [root@bigdata04 conf]# vim avro-to-hdfs.conf |
模拟数据源
1 | 三台机器中的Flume Agent都配置好了,在开始启动之前需要先在bigdata02和bigdata03中生成测试数据,为了模拟真实情况,在这里我们就开发一个脚本,定时向文件中写数据 |
bigdata02
1 | [root@bigdata02 log]# vim SimulateData.sh |
bigdata03
1 | 接着在bigdata03上创建/data/log目录,然后创建 generateAccessLog.sh 脚本 |
1 | 同上 |
启动进程
1 | 接下来开始启动相关的服务进程 |
启动bigdata04
1 | 1 [root@bigdata04 apache-flume-1.9.0-bin]# bin/flume-ng agent --name a1 --conf-file conf/avro-to-hdfs.conf -Dflume.root.logger=INFO,console |
启动bigdata02
1 | 1 [root@bigdata04 apache-flume-1.9.0-bin]# bin/flume-ng agent --name a1 --conf-file conf/file-to-avro.conf -Dflume.root.logger=INFO,console |


启动bigdata03
1 | 1 [root@bigdata04 apache-flume-1.9.0-bin]# bin/flume-ng agent --name a1 --conf-file conf/file-to-avro.conf -Dflume.root.logger=INFO,console |

注意
1 | 1.shell脚本 |
结果查看



1 | 注意:启动之后稍等一会就可以看到数据了,我们观察数据的变化,会发现hdfs中数据增长的不是很快,它会每隔一段时间添加一批数据,实时性好像没那么高? |



