第2章 极速上手Flume使用 采集文件内容到HDFS
1 | 接下来我们来看一个工作中的典型案例: |
source
Spooling Directory Source

1 | channels和type肯定是必填的,还有一个是spoolDir,就是指定一个监控的目录 |
channel
1 | 接下来是channel了 |
File Channel
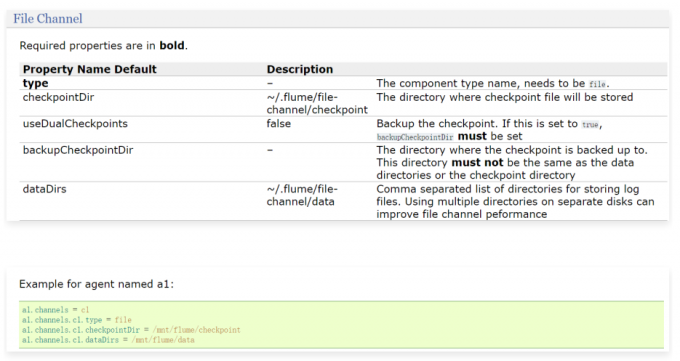
1 | 根据这里的例子可知,主要配置checkpointDir和dataDir,因为这两个目录默认会在用户家目录下生成,建议修改到其他地方 |
Sink
1 | 最后是sink |
HDFS

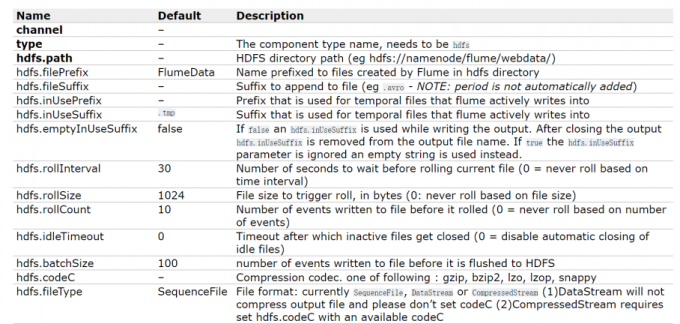
1 | hdfs.path是必填项,指定hdfs上的存储目录 |
1 | 除了这些参数以外,还有三个也比较重要 |
配置文件
1 | # Name the components on this agent |
测试文件
1 | 下面就可以启动agent了,在启动agent之前,先初始化一下测试数据 |
启动Agent
1 | 启动之前,先启动hadoop |
异常
1 | 2020-05-02 15:36:58,283 (conf-file-poller-0) [ERROR - org.apache.flume.node.P |
1 | 但是发现在启动的时候报错,提示找不到SequenceFile,但是我们已经把fileType改为了DataStream, |
1 | [root@bigdata01 soft]# scp -rq hadoop-3.2.0 192.168.182.103:/data/soft/ |
1 | 注意:还需要修改环境变量,配置HADOOP_HOME,否则启动Agent的时候还是会提示找不到SequenceFile |
再次启动Agent
1 | 此时可以看到Agent正常启动 |
1 | 此时发现文件已经生成了,只不过默认情况下现在的文件是 .tmp 结尾的,表示它在被使用,因为Flume只要采集到数据就会向里面写,这个后缀默认是由 hdfs.inUseSuffix 参数来控制的。 |
1 | 所以此时Flume就会监控linux中的/data/log/studentDir目录,当发现里面有新文件的时候就会把数据采集过来。 |
1 | [root@bigdata04 studentDir]# cd data/ |
1 | 发现里面有一个 log-1 的文件,这个文件中存储的其实就是读取到的内容,只不过在这无法直接查看。 |
1 | 那我再重启Agent之后,会不会再给加上.tmp呢,不会了,每次停止之前都会把所有的文件解除占用状态,下次启动的时候如果有新数据,则会产生新的文件,这其实就模拟了一下自动切文件之后的效果。 |
异常
1 | Flume v1.9.0启动报错ERROR - org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:459) |

