第七周 第1章 极速入门
什么是Flume
1 | 先来看一下官方解释 |
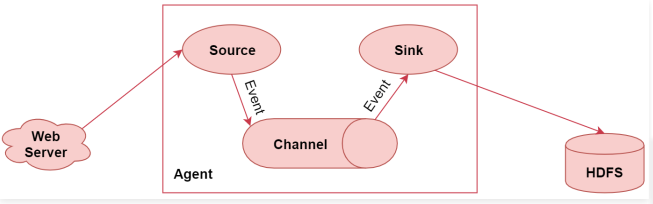
1 | 左边的web server表示是一个web项目,web项目会产生日志数据,通过中间的Agent把日志数据采集到HDFS中。 |
Flume的特性
1 | 1. 它有一个简单、灵活的基于流的数据流结构,这个其实就是刚才说的Agent内部有三大组件,数据通过这三大组件流动的 |
Flume高级应用场景
1 | 前面我们分析了Flume的典型常见应用场景,下面来看一下Flume的高级应用场景 |
一对多的输出
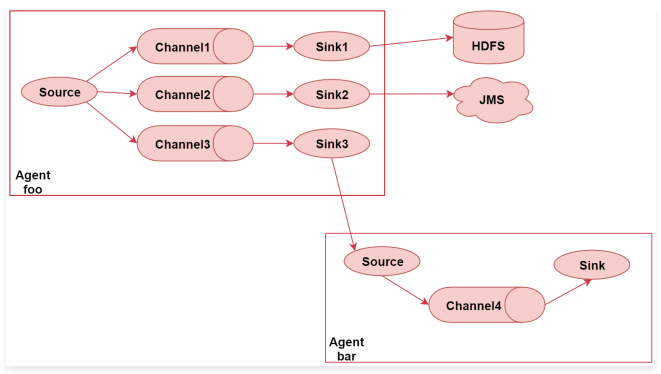
1 | 下面来详细分析一下 |
1 | 所以sink3就把数据输出到了Agent bar中 |
flume的汇聚功能
1 | 接着再看下面这张图,这张图主要表示了flume的汇聚功能,就是多个Agent采集到的数据统一汇聚到一个Agent |
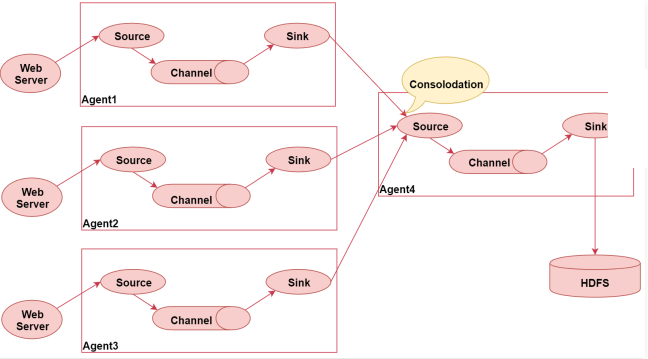
1 | 下面来详细分析一下, |
Flume的三大核心组件
1 | Flume的三大核心组件: |
Source
1 | Source:数据源:通过source组件可以指定让Flume读取哪里的数据,然后将数据传递给后面的channel |
Exec Source
1 | 在这我们挑几个常用的看一下: |
NetCat TCP/UDP Source
1 | NetCat TCP/UDP Source: 采集指定端口(tcp、udp)的数据,可以读取流经端口的每一行数据 |
Spooling Directory Source
1 | 采集文件夹里新增的文件 |
Kafka Source
1 | 从Kafka消息队列中采集数据 |
1 | 注意了,前面我们分析的这几个source组件,其中exec source 和 kafka source在实际工作中是最常见的,可以满足大部分的数据采集需求。 |
channel
1 | Channel:接受Source发出的数据,可以把channel理解为一个临时存储数据的管道 |
Memory Channel
1 | Memory Channel:使用内存作为数据的存储 |
File Channel
1 | File Channel:使用文件来作为数据的存储 |
Spillable Memory Channel
1 | Spillable Memory Channel:使用内存和文件作为数据存储,即先把数据存到内存中,如果内存中数据达到阈值再flush到文件中 |
sink
1 | Sink:从Channel中读取数据并存储到指定目的地 |
常用的sink组件有
1 | Logger Sink:将数据作为日志处理,可以选择打印到控制台或者写到文件中,这个主要在测试的时候使用 |
Flume安装部署
下载
Flume安装部署
1 | 想要使用Flume采集数据,那肯定要先安装Flume |

1 | 安装包下载好以后上传到linux机器的/data/soft目录下,并且解压 |

