MapReduce实验

案例一 wordcount
准备工作
jar包导入
1.将mapreduce的jar包复制到eclipse的hadoop项目的lib里
/usr/hadoop/…/share/mapreduce/
/home/…/hadoop/lib/
2.打开eclipse,在项目上单击右键,build path -> configure ..->libraries->add external jars
编写wordcount的map()和reduce()函数
map()
1 | package sudo.edu.hadoop.mapreduce.wordCount; |
reduce()
1 | package sudo.edu.hadoop.mapreduce.wordCount; |
main()
1 | package sudo.edu.hadoop.mapreduce.wordCount; |
案例二 各部门员工薪水总和


1 | 7369,SMITH,CLERK,7902,1980/12/17,800,,20 |
mapper
1 | package saltotal; |
reducer
1 | package saltotal; |
主程序入口
1 | package saltotal; |
案例三 序列化和反序列化
1 | 序列化是一种将内存中的Java对象转化为其他可存储文件或可跨计算机传输数据流的一种技术。 |
1 | Hadoop 的序列化则是实现 org.apache.hadoop.io.Writable 接口,该接口包含 readFields()、 |
1 | MapReduce 中涉及的 k1、v1、k2、v2、k3、v3、k4、v4 都需要序列化,意味着需要实现 Writable |
Employee
1 | package sudo.edu.hadoop.mapreduce.employeeDemo.serializable; |
Mapper
1 | package sudo.edu.hadoop.mapreduce.employeeDemo.serializable; |
Reducer
1 | package sudo.edu.hadoop.mapreduce.employeeDemo.serializable; |
Main
1 | package sudo.edu.hadoop.mapreduce.employeeDemo.serializable; |
分区
Mapper 划分数据的过程称作为分区( Partition),负责实现划分的数据的类称为 Partitioner。
MapReduce 默认的 Partitioner 是 HashPartitioner
partitioner
1 | package sudo.edu.hadoop.mapreduce.employee.partitioner; |
Employee
1 | package sudo.edu.hadoop.mapreduce.employee.partitioner; |
Mapper
1 | package sudo.edu.hadoop.mapreduce.employee.partitioner; |
Reducer
1 | package sudo.edu.hadoop.mapreduce.employee.partitioner; |
Main
1 | package sudo.edu.hadoop.mapreduce.employee.partitioner; |
结果

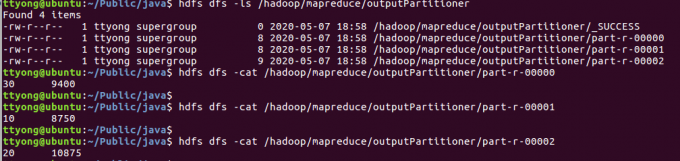
合并
排序
又要排序又要序列化直接继承WritableComparable类; 这个接口继承自writable和comparable接口
Main
1 | package sudo.edu.hadoop.mapreduce.employee.sort; |
Mapper
1 | package sudo.edu.hadoop.mapreduce.employee.sort; |
Employee
1 | package sudo.edu.hadoop.mapreduce.employee.sort; |
MapReduce 编程案例
排序
1 | 查看员工的薪资,按部门、薪资升序排序。 |
1 | 但如果 key 属于某个自定义类,且期望 key 按某个方式进行排序,此时这个自定义类就要实 |
Mapper 类
1 | package sort.object; |
1 | get()方法是用来获取NullWritable的实例的。NullWritable是Writable的一个特殊类,它的实现方法为空实现,不从数据流中读数据,也不写入数据,只充当占位符。在MapReduce中,如果你不需要使用键或值,你就可以将键或值声明为NullWritable。它是一个不可变的单实例类型¹。 |
Employee类
1 | package sort.object; |
程序主入口
1 | package sort.object; |
提交作业到集群运行
1 | hadoop jar objSort-1.0-SNAPSHOT.jar /input/emp.csv /output/sort |
1 | 在HDFS文件中,这个程序的输出将以文本形式存储。每一行都代表一个键值对,其中键和值之间用制表符分隔。由于值是NullWritable的实例,所以它不会被写入输出文件。 |
去重
1 | 获取员工表所有的 job 信息,并且要求仅列出不同的值。类似 SQL 语句: |
1 | 如果 k2 是 job,那么 Reducer 的输入 k3,就是去掉重复后的 job,而 v2 的类型用 NullWritable |
Mapper 类
1 | package distinct; |
Reducer 类
1 | package distinct; |
程序主入口
1 | package distinct; |
提交作业到集群运行
1 | hadoop jar distinct-1.0-SNAPSHOT.jar /input/emp.csv /output/distinct |
多表查询

1 | 采用MapReduce实现类似下面SQL语句的功能: |
1 | (1)Map 端读取所有的文件,并为输出的内容加上标识,代表文件数据来源于员工表或部门 |
Mapper 类
1 | package equaljoin; |
Reducer 类
1 | package equaljoin; |
程序主入口
1 | package equaljoin; |
提交作业到集群运行
1 | hadoop jar equaljoin-1.0-SNAPSHOT.jar /inputjoin/ /output/join |
使用 MapReduce 求出各年销售笔数、各年销售总额
1 | 字段名 类型 是否能为空 备注 |
1 | public class SalesMapper extends Mapper<LongWritable, Text, IntWritable, FloatWritable> { |
使用 MapReduce 统计用户在搜狗上的搜索数据
人穷没入群,言轻莫劝人。

