Hive(重点)
Hive简介
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行
Hive是一个翻译器:SQL —> Hive引擎 —> MapReduce程序
Hive是构建在HDFS上的一个数据仓库(Data Warehouse)
为什么要使用Hive?
直接使用 MapReduce 所面临的问题:
1、人员学习成本太高
2、项目周期要求太短
3、MapReduce实现复杂查询逻辑开发难度太大
为什么要使用 Hive:
1、更友好的接口:操作接口采用类 SQL 的语法,提供快速开发的能力。
2、更低的学习成本:避免了写 MapReduce,减少开发人员的学习成本,使
DBA、运维人员可以通过SQL来实现操作大数据。
3、更好的扩展性:可自由扩展集群规模而无需重启服务,还支持用户自定
义函数。
安装Hive
Metastore三种运行模式
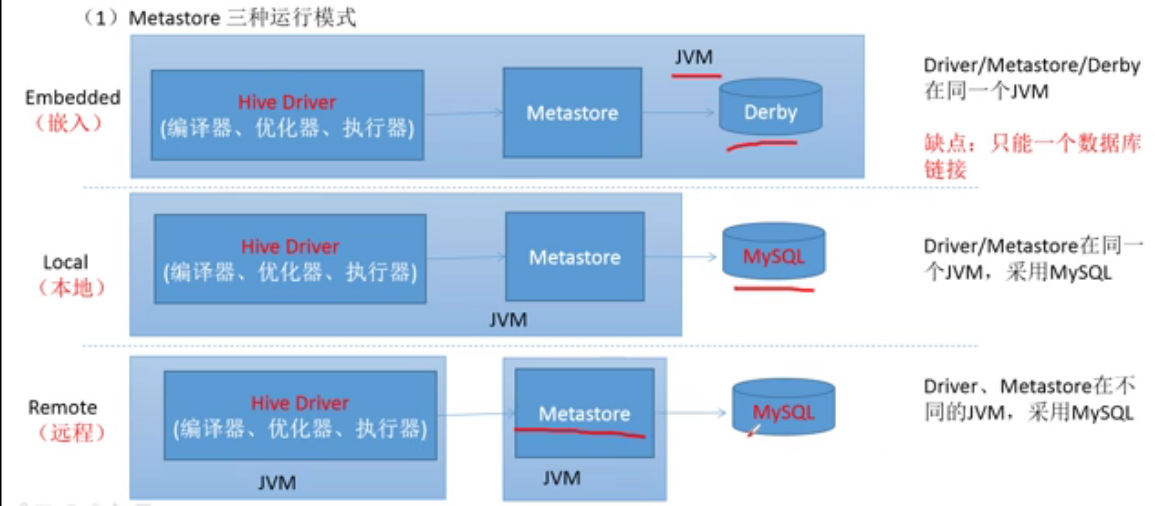
了解Metastore配置属性

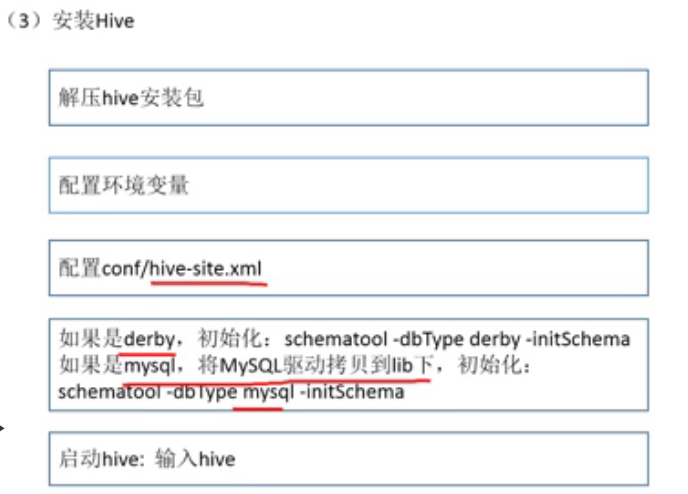
安装Hive
Hive的架构与工作原理
Hive体系结构
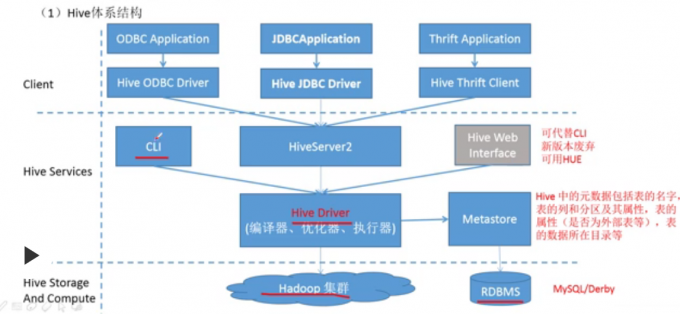
CLI(终端):常采用这个
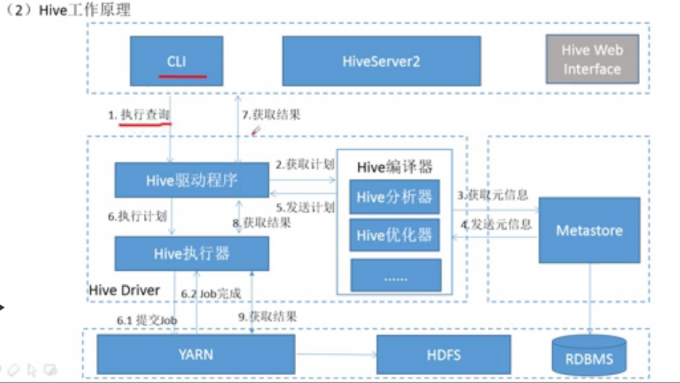
Hive工作原理
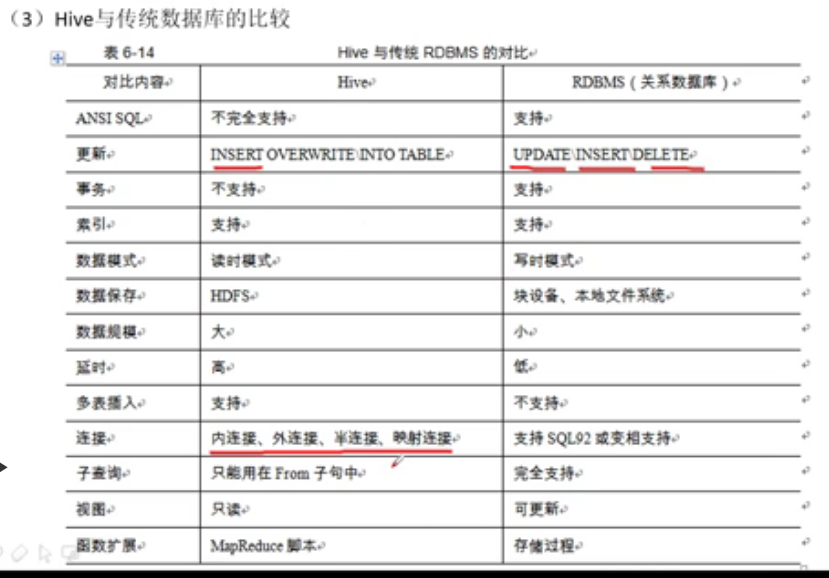
Hive与传统数据库的比较
HiveQL
Hive支持的数据类型

建表命令
1 | CREATE TABLE 表名(...) |

数据加载命名
导入HDFS数据

会把hdfs中对应文件移动到hive仓库中
导入本地数据

复制
数据模型
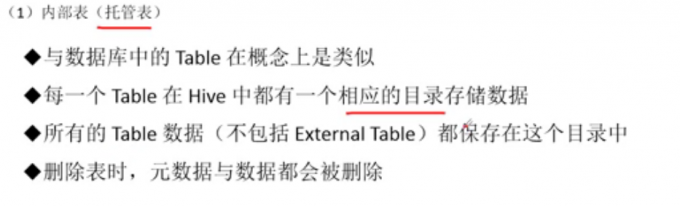
内部表(托管表)
特点
创建内部表

外部表
特点

创建外部表

分区表

桶表

临时表

视图
特点

创建

数据查询

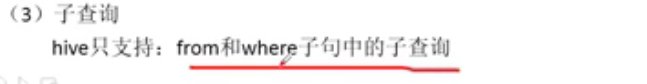
条件函数

Hive不支持数据删除和修改
用户自定义函数


Hive如何调优


