初识 Hadoop 大数据技术
大数据技术概述
大数据产生的背景
计算机诞生; 互联网发展
大数据的定义
“大数据”是一个涵盖多种技术的概念,简单地说,是指无法在一定时间内用常规软件工具对
其内容进行抓取、管理和处理的数据集合。
IBM 公司将“大数据”理念定义为 4 个 V,即大量化( Volume)、多样化( Variety)、快速化( Velocity)及由此产生的价值( Value)。
- 数据体量大:大数据的数据量从 TB 级别跃升到 PB 级别。
- 数据类型多:大数据的数据类型包括前文提到的网络日志、视频、图片、地理位置信息等。
- 处理速度快: 1 秒定律。最后这一点是大数据技术与传统数据挖掘技术的本质区别。
- 价值密度低:以视频为例,连续不间断监控过程中,可能有用的数据仅仅有一两秒
大数据技术的发展
大数据技术要面对的基本问题,也是最核心的问题,就是海量数据如何可靠存储和如何高效计算的问题。
Google 的“三驾马车”
GFS 的思想
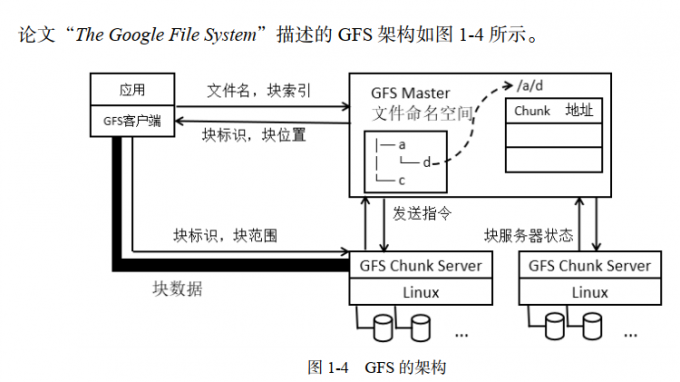
论文“The Google File System”描述了一个分布式文件系统的设计思路
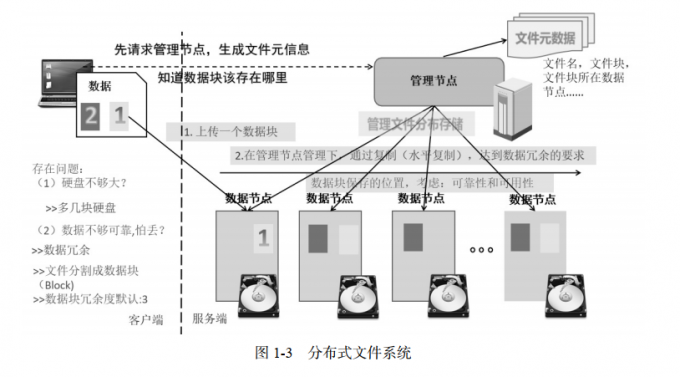
从交互实体上划分,分布式文件系统有两个基本组成部分,一个是客户端( Client),一个是服务端( Server).
如果客户端把文件上传到服务端,但是服务端的硬盘不够大,怎么办? 多加硬盘,或多增加主机
数据的存储可靠性怎么保证? 数据冗余存储
主机或硬盘如何被管理起来? 管理节点
GFS 解决这些问题的思路是这样的,增加一个管理节点,去管理这些存放数据的主机。存放数据的主机称为数据节点。 而上传的文件会按固定的大小进行分块。 数据节点上保存的是数据块,而非独立的文件。数据块冗余度默认是 3。上传文件时,客户端先连接管理节点,管理节点生成数据块的信息,包括文件名、文件大小、上传时间、数据块的位置信息等。这些信息称为文件的元信息,它会保存在管理节点。客户端获取这些元信息之后,就开始把数据块一个个上传。客户端把数据块先上传到第一个数据节点,然后,在管理节点的管理下,通过水平复制,复制几份数据块到其他节点,最终达到冗余度的要求。水平复制需要考虑两个要求:可靠性、可用性.
MapReduce 的思想
PageRank,即网页排名,又称网页级别
MapReduce 采用“分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个子节点共同完成,然后整合各个子节点的中间结果,得到最终的计算结果。简而言之, MapReduce 就是“分散任务,汇总结果”

