第十周 第2章 解读spark工作与架构原理
Spark的工作原理
1 | 下面我们来分析一下Spark的工作原理 |
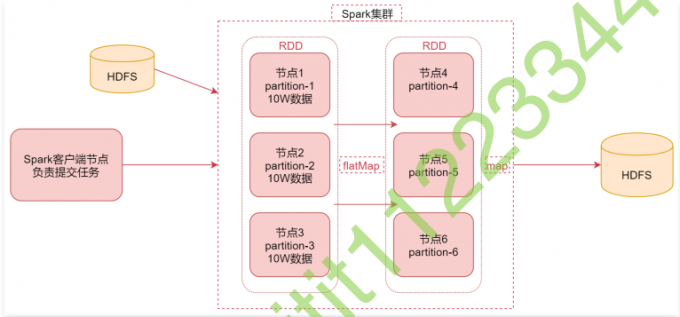
1 | 首先看中间是一个Spark集群,可以理解为是Spark的stand alone集群,集群中有6个节点 |
1 | 假设我们现在从HDFS中读取的这份数据被转化为RDD之后,在RDD中分成了3份,那这3份数据可能会分布在3个不同的节点上面,对应这里面的节点1、节点2、节点3 |
1 | 假设现在这个RDD中每个分区中的数据有10w条 |
什么是RDD
1 | RDD通常通过Hadoop上的文件,即HDFS文件进行创建,也可以通过程序中的集合来创建 |
RDD的特点
1 | 弹性:RDD数据默认情况下存放在内存中,但是在内存资源不足时,Spark也会自动将RDD数据写入磁盘 |
Spark架构相关进程
1 | 下面我们来看一下Spark架构相关的进程信息 |
1 | Driver: |
Spark架构原理
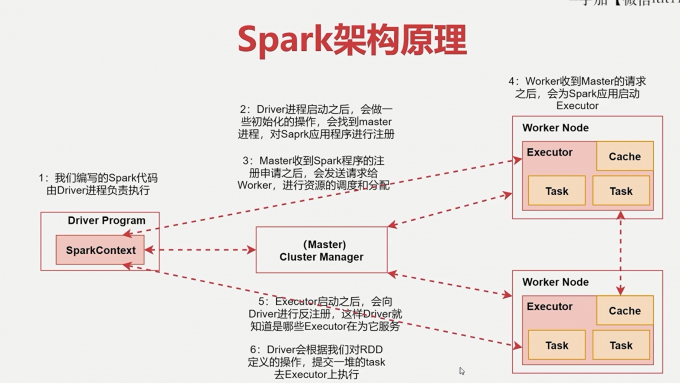
1 | 下面来看一个图,通过刚才那几个进程,我们来分析一下Spark的架构原理 |
1 | 1. 首先我们在spark的客户端机器上通过driver进程执行我们的Spark代码 |

