第十周 第1章 初识spark
快速了解Spark
什么是Spark
1 | Spark是一个用于大规模数据处理的统一计算引擎 |
Spark的特点
Speed:速度快
1 | 由于Spark是基于内存进行计算的,所以它的计算性能理论上可以比MapReduce快100倍 |
Easy of Use:易用性

1 | Spark的易用性主要体现在两个方面 |
Generality:通用性

1 | Spark提供了Core、SQL、Streaming、MLlib、GraphX等技术组件,可以一站式地完成大数据领域的离线批处理、SQL交互式查询、流式实时计算,机器学习、图计算等常见的任务 |
Runs Everywhere:到处运行
1 | 你可以在Hadoop YARN、Mesos或Kubernetes上使用Spark集群。 |
Spark vs Hadoop
1 | 那接下来我们拿Spark和Hadoop做一个对比 |
1 | 之前有一种说法,说Spark将会替代Hadoop,这个说法是错误的,其实它们两个的定位是不一样的,Spark是一个通用的计算引擎,而Hadoop是一个包含HDFS、MapRedcue和YARN的框架,所以说Spark就算替代也只是替代Hadoop中的MapReduce,也不会整个替代Hadoop,因为Spark还需要依赖于Hadoop中的HDFS和YARN。 |
Spark+Hadoop
1 | 那下面我们来看一下Spark和Hadoop是如何结合 |
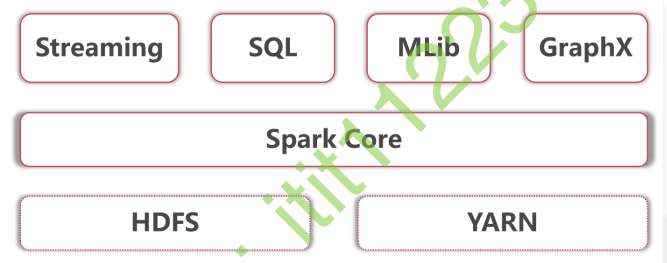
1 | 底层是Hadoop的HDFS和YARN |
1 | 其实这里面这么多模块,针对大数据开发岗位主要需要掌握的是Spark core、streaming、sql这几个模块,其中Mlib主要是搞算法的岗位使用的,GraphX这个要看是否有图计算相关的需求,所以这两个不是必须要掌握的。 |
Spark集群安装部署
1 | 前面我们对Spark有一个整体概念之后,下面我们来安装部署一下Spark,spark也是支持集群模式的 |
1 | Spark集群有多种部署方式,比较常见的有Standalone模式和ON YARN模式 |
1 | 在这需要注意选择合适的安装包 |

1 | 目前spark有三大版本,1.x,2.x和3.x,其中3.x是一个预览版本,不能在生产环境中使用,所以目前使用最多的就是2.x的版本了 |


stand alone
1 | 由于Spark集群也是支持主从的,在这我们使用三台机器,部署一套一主两从的集群 |
1 | 注意:需要确保这几台机器上的基础环境是OK的,防火墙、免密码登录、还有JDK |
1 | 先在bigdata01上进行配置 |
1 | 7启动Spark集群 |
1 | 还可以访问主节点的8080端口来查看集群信息 |
1 | 10. 提交任务 |



1 | 需要使用bin目录下的spark-submit脚本提交任务 |
1 | 提交之后可以到Spark的8080 web界面查看任务信息 |

1 | 停止Spark集群 |
ON YARN
1 | ON YARN模式很简单,先保证有一个Hadoop集群,然后只需要部署一个Spark的客户端节点即可,不需要启动任何进程 |
1 | 注意:Spark的客户端节点同时也需要是Hadoop的客户端节点,因为Spark需要依赖于Hadoop |
1 | 1. 将spark-2.4.3-bin-hadoop2.7.tgz上传到bigdata04的/data/soft目录中 |

1 | 6. 可以到YARN的8088界面查看提交上去的任务信息 |

