第八周 第4章 Hive核心实战
Hive中数据库的操作
1 | show databases; |
1 | default是默认数据库,默认就在这个库里面 |

1 | 它的默认值是 /user/hive/warehouse ,表示hive的default默认数据库对应的hdfs存储目录。 |

1 | 这个默认数据库的信息在Metastore中也有记录,在dbs表中 |



1 | 如果你不希望创建的数据库在这个目录下面,想要手工指定,那也是可以的,在创建数据库的时候通过location来指定hdfs目录的位置 |

Hive中表的操作
创建表
1 | create table xxx(id int); |
查看创建的表
1 | 查看表信息 |
查看表结构信息
1 | desc xxx; |
查看表的创建信息

1 | show create table xxx; |
1 | 到metastore中看一下 |


1 | 在表COLUMNS_V2中存储的是Hive表的字段信息(包含字段注释、字段名称、字段类型、字段顺序) |

修改表名
1 | hive (default)> alter table t2 rename to t2_bak; |
加载数据
1 | 咱们前面向表中添加数据是使用的insert命令,其实使用insert向表里面添加数据只是在测试的时候使用,实际中向表里面添加数据很少使用insert命令的 |
1 | [root@bigdata04 hivedata]# pwd |
1 | 我们到hdfs上去看一下这个表,发现刚才的文件其实就是上传到了t2_bak目录中 |
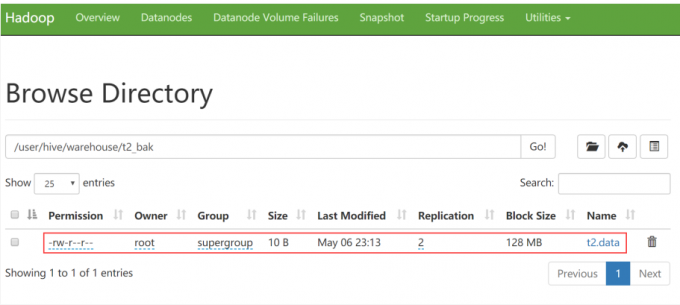
1 | 那我们自己手工通过put命令把数据上传到t2_bak目录中可以吗? |
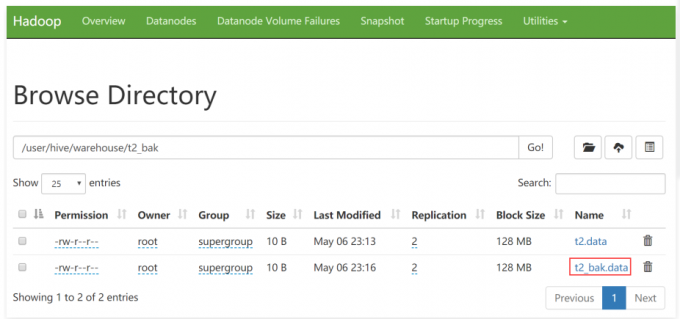
1 | 再查询一下这个表的数据,可以发现数据多了一份,说明刚才使用hdfs的put命令上传的是可以的。 |
表增加字段及注释、删除表
增加字段
1 | 在工作中会有给已存在的表增加字段的需求,需要使用alter命令 |
1 | hive (default)> alter table t2_bak add columns (name string); |
增加注释
1 | 现在我们通过desc查询表中的字段信息发现都没有注释,所以想要给字段加一些注释,以及表本身也可以增加注释,都是使用comment关键字 |
1 | create table t2( |
1 | 查看这个表的信息,结果发现我们添加的中文注释都是乱码 |
1 | 原因是什么?怎么破? |
1 | 登陆Mysql数据库切换到Hive库: |
1 | 确认一下现在表COLUMNS_V2和TABLE_PARAMS的编码,都是latin1 |
1 | 修改这两张表的编码即可; |
1 | 这样修改之后以后就可以看到中文注释了。 |
指定列和行分隔符的指定
1 | 在我们实际工作中,肯定不会像上面一样创建一张非常简单的表,实际中表的字段会比较多,下面我们就来创建一个多字段的表t3 |
1 | hive (default)> load data local inpath '/data/soft/hivedata/t3.data' into table t3; |
1 | 重新加载数据,查询表数据,这个时候发现刚才修改的那条数据被成功解析了 |
1 | 那么问题来了,为了我们能够在上传数据之后让hive表正确识别数据,那我们该如何修改hive表的默认分隔符呢? |
1 | 把t3.data文件中的字段分隔符都恢复为制表符,然后重新把数据加载到t3_new表中。 |
1 | hive (default)> select * from t3_new; |

