第八周 第4章 Hive核心实战
Hive中的表类型
1 | 在Mysql中没有表类型这个概念,因为它就只有一种表。 |
内部表
1 | 首先看内部表 |
外部表
1 | 建表语句中包含External的表叫外部表 |




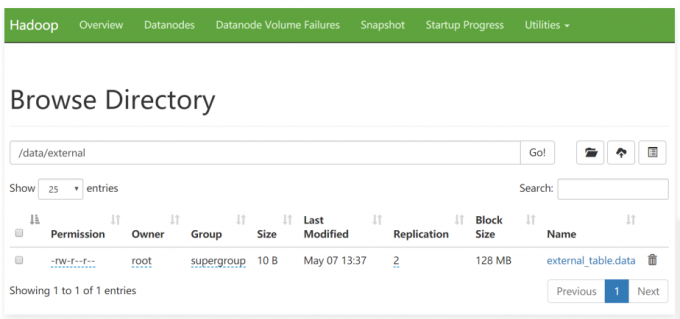
1 | 官网中的案例如下: |
1 | [root@bigdata04 hivedata]# more external_table.data |
1 | 接下来尝试删除这个表,看看会发生什么现象 |

1 | 这个其实就是前面我们所说的外部表的特性,外部表被删除时,只会删除表的元数据,表中的数据不会被删除。 |
1 | 在hive中查询目前所有的表信息,发现external_table表确实被删除了 |

内部表和外部表相互转化
1 | 注意:实际上内外部表是可以互相转化的,需要我们做一下简单的设置即可。 |
分区表
单个分区字段
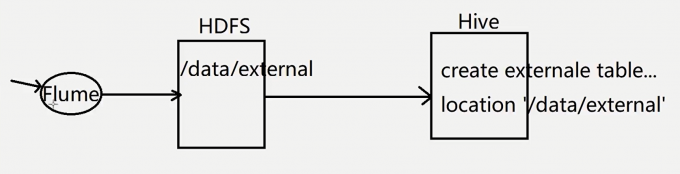
1 | 假设我们的web服务器每天都产生一个日志数据文件,Flume把数据采集到HDFS中,每一天的数据存储到一个日期目录中。我们如果想查询某一天的数据的话,hive执行的时候默认会对所有文件都扫描一遍,然后再过滤出来我们想要查询的那一天的数据 |
1 | create table partition_1 ( |

加载数据时自动创建分区
1 | 数据格式是这样的 |
1 | 来查看一下hdfs中的信息,刚才创建的分区信息在hdfs中的体现是一个目录。 |

手动创建分区
1 | 当然我也可以手动在表中只创建分区: |
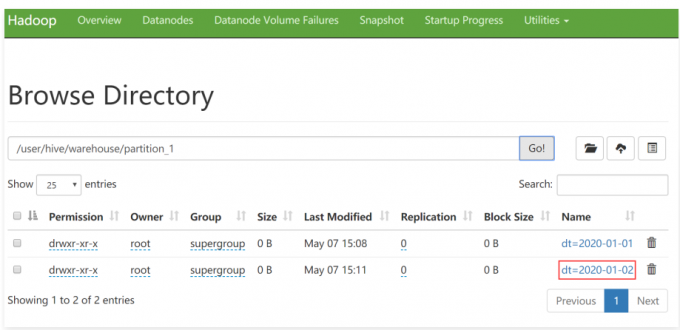
1 | 向这个分区中添加数据,可以使用刚才的load命令或者hdfs的put命令都可以 |
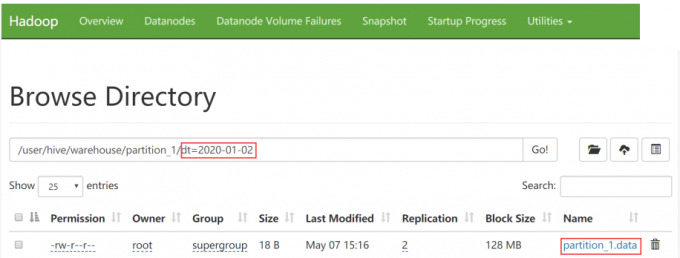
查看表的分区
1 | 如何查看我的表中目前有哪些分区呢,语法为: show partitions tblName |
删除分区
1 | 那问题来了,刚才增加了一个分区,那我能删除一个分区吗? |
1 | 注意了,此时分区删除之后,分区中对应的数据也就没有了,因为是内部表,所以分区的数据是会被删掉的 |
多个分区字段
1 | 刚才呢,我们创建了一个分区,但是有的业务需求,需要创建多个分区,可以吗? |
1 | create table partition_2 ( |
1 | hive (default)> desc partition_2; |
1 | 数据文件内容 |
1 | 注意:数据文件中只需要有id和name这两个字段的值就可以了,具体year和school这两个分区字段是在加载分区的时候指定的。 |
1 | hive (default)> load data local inpath '/data/soft/hivedata/partition_2.data' into partition_2 patition(year=2020, school="xk") |
1 | 查看分区信息 |
查询分区表
1 | 前面我们讲了如何创建、增加和删除分区 |
1 | 这就是分区表的主要操作 |




外部分区表
1 | 外部分区表示工作中最常用的表 |
1 | 其它的操作和前面操作普通分区表是一样的,我们主要演示一下添加分区数据和删除分区的操作 |
1 | 删除分区(删除后,此时hdfs上的分区目录还在) |
1 | 注意:此时分区目录的数据还是在的,因为这个是外部表,所以删除分区也只是删除分区的定义,分区中的数据还是在的,这个和内部分区表就不一样了 |

1 | 如果数据已经上传上去了,如何给他们绑定关系呢?就是使用前面咱们讲的alter add partition命令,注意在这里需要通过location指定分区目录 |
1 | 此时再查询分区数据和表数据,就正常了。 |
总结
1 | load data local inpath '/data/soft/hivedata/ex_par.data' into table ex_par partition(dt='20200101'); |
1 | 外部分区表是工作中最常见的表 |
经验
1 | 1.在实际工作中,我们在hive中创建的表95%以上的都是外部表 |
桶表
1 | 桶表是对数据进行哈希取值,然后放到不同文件中存储 |
创建桶表
1 | 下面来建立一个桶表: |
1 | 这个时候往桶中加载数据的时候,就不能使用load data的方式了,而是需要使用其它表中的数据,那么给桶表加载数据的写法就有新的变化了。 |
1 | 初始化一个表,用于向桶表中加载数据 |
1 | hive (default)> create table b_source(id int); |
向桶表加载数据
1 | 向桶表中加载数据 |
查看结果
1 | hive (default)> select * from bucket_tb; |
1 | 按照我们设置的桶的数量为4,这样在hdfs中会存在4个对应的文件,每个文件的大小是相似的 |

1 | 到hdfs上查看桶表中的文件内容,可以看出是通过对buckets取模确定的 |

1 | 这样就实现了数据分桶存储。 |
桶表的作用
数据抽样
1 | 数据抽样 |
1 | bucket 1 out of 4 on id:根据id对桶表中的数据重新分桶,分成4桶,取出第1桶的数据 |

提高某些查询效率
1 | 例如:join查询,可以避免产生笛卡尔积的操作 |
临时表
1 | 一般用普通内部表做临时表使用 |
视图
1 | Hive中,也有视图的概念,那我们都知道视图实际上是一张虚拟的表,是对数据的逻辑表示,它的主要作用是为了降低查询的复杂度。 |
1 | 那我们在Hive中如何来创建一个视图呢? |
创建视图
1 | hive (default)> create view v1 as select t3_new.id,t3_new.stu_name from t3_new; |
查询视图
1 | 查看视图的结构,显示的内容和表显示的内容是没有区别的 |
1 | 注意:视图在/user/hive/warehouse中是不存在的。因为它只是一个虚拟的表 |
删除视图
1 | drop view v1; |
综合案例
1 | 接下来我们来看一个综合案例,主要使用外部分区表和视图实现 |

1 | 这里面的数据是json格式的,也是有规律的,如果我们在建表的时候该怎么创建? |

1 | 针对json格式的数据建表的时候没办法直接把每个字段都定义出来 |
1 | 在这里我们需要提前涉及一个函数get_json_object,这个函数可以从json格式的数据中解析出指定字段 |
建表
1 | create external table ex_par_more_type( |
1 | 加载数据 【注意,此时的数据已经通过flume采集到hdfs中了,所以不需要使用load命令了,只需要使用一个alter命令添加分区信息就可以了,但是记得要把那三个子目录都添加进去】 |

1 | 可以先查询一下数据,可以查询出来,说明前面的配置没有问题。 |

创建视图
1 | 接下来就是重点了,需要创建视图,在创建视图的时候从数据中查询需要的字段信息 |
1 | giftRecord类型的视图 |

1 | userInfo类型的视图 |


1 | videoInfo类型的视图 |


1 | 注意:此时在SQL后面加不加日期都是一样的,因为现在只有这一天的数据 |
创建定时器
1 | 后面想要查询数据就直接通过视图,指定日期查询就可以了,不指定日期的话会查询这个类型下面所有的数据。 |
1 | [root@bigdata04 hivedata]# vi addPartition.sh |


1 | 不指定if not exists时,当存在分区时会报错 |

1 | 加-x 更清晰 |


1 | 配置crontab |

1 | 这就是一个完整的开发流程,针对需要多次执行的sql一般都是需要配置到脚本中使用hive -e去执行的。 |

