第七周 第3章 精讲Flume高级组件
1 | 前面我们掌握了Flume中的核心组件 source、channel、sink的使用,下面我们来学习一下Flume中的一些高级组件的使用 |
高级组件
1 | Source Interceptors:Source可以指定一个或者多个拦截器按先后顺序依次对采集到的数据进行处 |
1 | 在具体分析这些高级组件之前,我们先插播一个小知识点,这个知识点在高级组件中会用到 |
1 | Event是Flume传输数据的基本单位,也是事务的基本单位,在文本文件中,通常一行记录就是一个Event |
Source Interceptors
1 | 接下里我们看一下第一个高级组件,Source Interceptors |
1 | Timestamp Interceptor:向event中的header里面添加timestamp 时间戳信息 |
1 | 根据刚才的分析,总结一下: |
案例
1 | 下面呢,我们来看一个案例:对采集到的数据按天按类型分目录存储 |
1 | video_info |
1 | 这份数据中有三种类型的数据,视频信息、用户信息、送礼信息,数据都是json格式的,这些数据还有一个共性就是里面都有一个type字段,type字段的值代表数据类型 |

1 | 这里的日期变量好获取,但是数据类型如何获取呢? |
流程
1 | 所以整体的流程是这样的 |

配置
1 | 那下面我们来配置Agent,在bigdata04机器上创建 file-to-hdfs-moreType.conf |



1 | #给三个组件起名 |
1 | 注意:这里面的拦截器,拦截器可以设置一个或者多个,source采集的每一条数据都会经过所有的拦截器进行处理,多个拦截器按照顺序执行。 |
1 | 后面也统一设置了hdfs文件的前缀和后缀 |

启动
1 | bin/flume-ng agent --name a1 --conf conf-file conf/file-to-hdfs -Dflume.root.logger=INFO |

结果查看
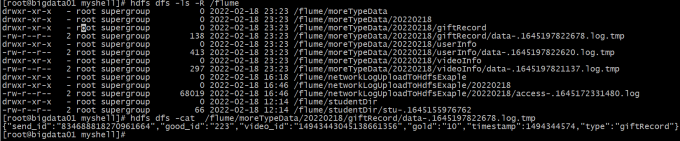
1 | 看一下HDFS中的文件内容,发现type字段的值确实被拦截器修改了 |
Channel Selectors
1 | 接下来看一下Channel Selectors |
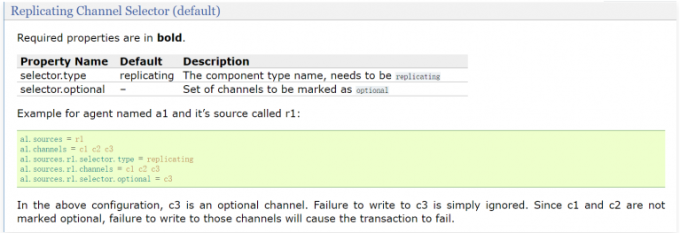
1 | 在这个例子的配置中,c3是可选channel。对c3的写入失败将被忽略。由于c1和c2未标记为可选,因此未能写入这些channel将导致事务失败 |
1 | 还有一个 channel选择器是Multiplexing Channel Selector,它表示会根据Event中header里面的值将 |
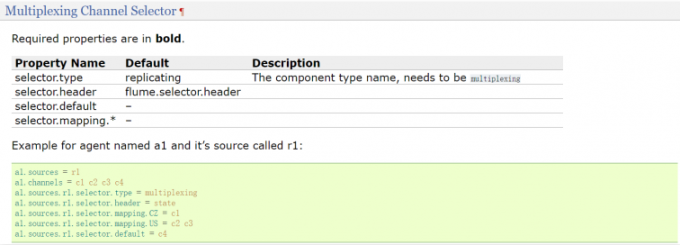
1 | 在这个例子的配置中,指定了4个channel,c1、c2、c3、c4 |
案例一:多Channel之Replicating Channel Selector
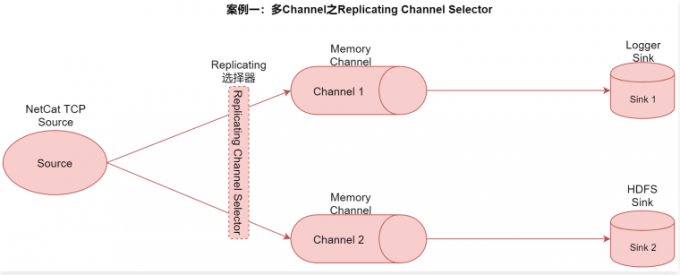
1 | 在这个案例中我们使用Replicating选择器,将source采集到的数据重复发送给两个channle,最后每个channel后面接一个sink,负责把数据存储到不同存储介质中,方便后期使用。 |
配置
1 | 下面根据图中列出来的source、channel和sink来配置agent |
1 | [root@bigdata04 conf]# vim tcp-to-replicatingchannel.conf |
启动,输入数据,查看

1 | 生成测试数据,通过telnet连接到socket |


案例二:多channel之Multiplexing Channel Selector案例
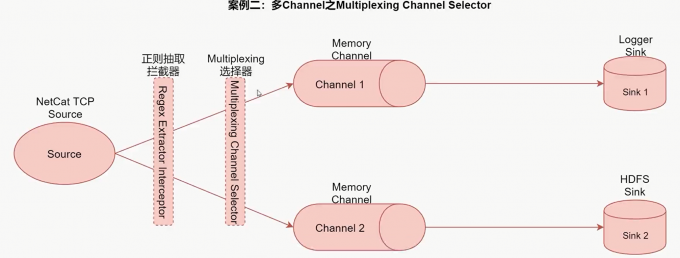
1 | 最终再把不同channel中的数据存储到不同介质中。 |
测试数据格式
1 | {"name":"jack","age":19,"city":"bj"} |
配置
1 | 下面来配置Agent,复制tcp-to-replicatingchannel.conf的内容, |
1 | [root@bigdata04 conf]# vim tcp-to-multiplexingchannel.conf |
启动,输入测试数据,查看




Sink Processors
1 | 接下来看一下Sink处理器 |
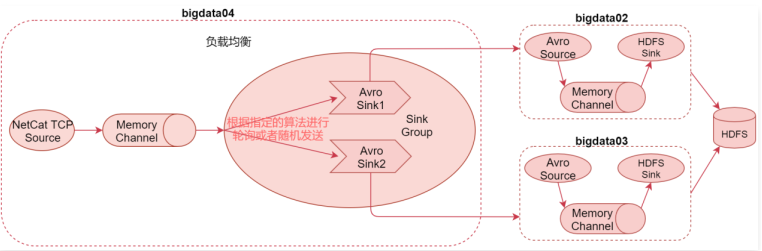
负载均衡案例:Load balancing Sink Processor
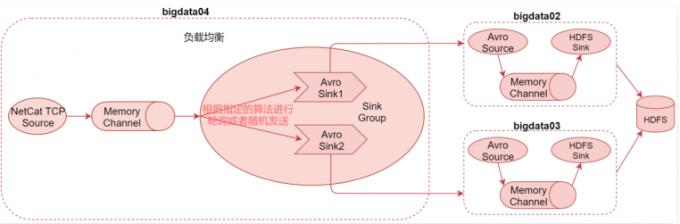
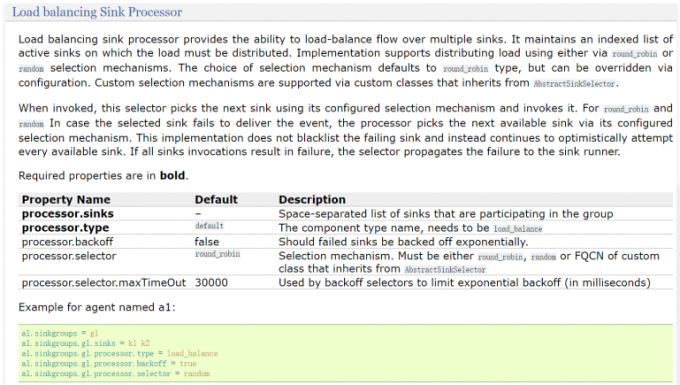
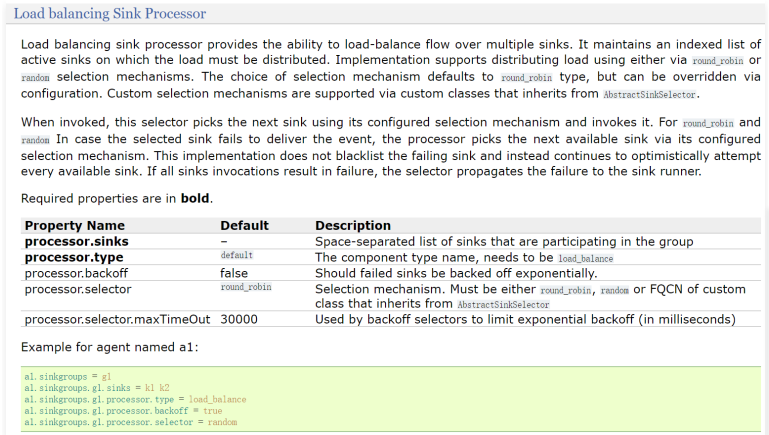
1 | 看中间的参数信息, |
配置
1 | 这个负载均衡案例可以解决之前单节点输出能力有限的问题,可以通过多个sink后面连接多个Agent实现负载均衡,如果后面的Agent挂掉1个,也不会影响整体流程,只是处理效率又恢复到了之前的状态。 |
bigdata04
1 | a1.sources=r1 |
1 | a1.sinks.k1.port = 45454和a1.sinks.k2.port = 41414的端口一致也没事,因为是在不同的节点上,只要bigdata02,bigdata03上写的一致就行 |
bigdata02
1 | # |
bigdata03
1 | # |
启动
1 | 还是先启动后面,再启动前面 |





异常
1 | java.lang.NoSuchMethodError:com.google.common.base.Preconditions.checkArgument(...)(已解决) |
结果查看



故障转移案例:Failover Sink Processor
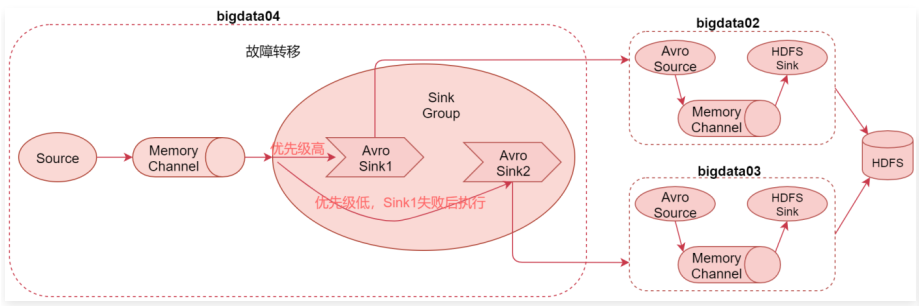
1 | 接下来我们来看一下故障转移 |
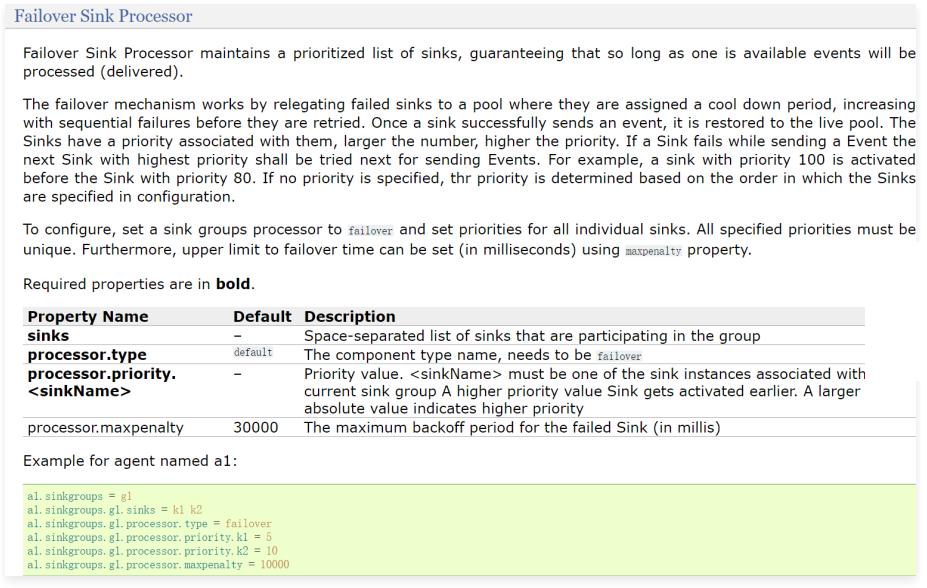
1 | processor.type:针对故障转移的sink处理器,使用failover |
配置
bigdata04
1 | 就sink配置策略改变 |
1 | a1.sources=r1 |
bigdata02
1 | 与上个案例一样,就hdfs地址改变 |
bigdata03
1 | 与上个案例一样,就hdfs地址改变 |
结果查看



1 | 然后到hdfs上验证数据,发现现在数据是通过bigdata03这台机器写出去的,因为对应bigdata03这台机 |
1 | 此时将优先级高的agent停了,在向端口发送数据,会用另一台机子发送数据,再启动优先级高的,又会恢复原样 |
模拟Agent挂掉
1 | 接下来模拟bigdata03这台机器上的的Agent挂掉,也就意味着k2这个sink写不出去数据了,此时,我们再通过socket发送一条数据,看看会怎么样 |


1 | 此时如果把bigdata03上的Agent再启动的话,会发现新采集的数据会通过bigdata03上的Agent写出去,这是因为它的优先级比较高。 |

