06讲新技术层出不穷,HDFS依然是存储的王者
1 | 我们知道,Google大数据“三驾马车”的第一驾是GFS(Google 文件系统),而Hadoop的第一个产品是HDFS,可以说分布式文件存储是分布式计算的基础,也可见分布式文件存储的重要性。如果我们将大数据计算比作烹饪,那么数据就是食材,而Hadoop分布式文件系统HDFS就是烧菜的那口大锅。 |
为什么HDFS的地位如此稳固呢?
1 | 在整个大数据体系里面,最宝贵、最难以代替的资产就是数据,大数据所有的一切都要围绕数据展开。HDFS作为最早的大数据存储系统,存储着宝贵的数据资产,各种新的算法、框架要想得到人们的广泛使用,必须支持HDFS才能获取已经存储在里面的数据。所以大数据技术越发展,新技术越多,HDFS得到的支持越多,我们越离不开HDFS。HDFS也许不是最好的大数据存储技术,但依然最重要的大数据存储技术。 |
1 | 那我们就从HDFS的原理说起,今天我们来聊聊HDFS是如何实现大数据高速、可靠的存储和访问的。 |
HDFS的架构图
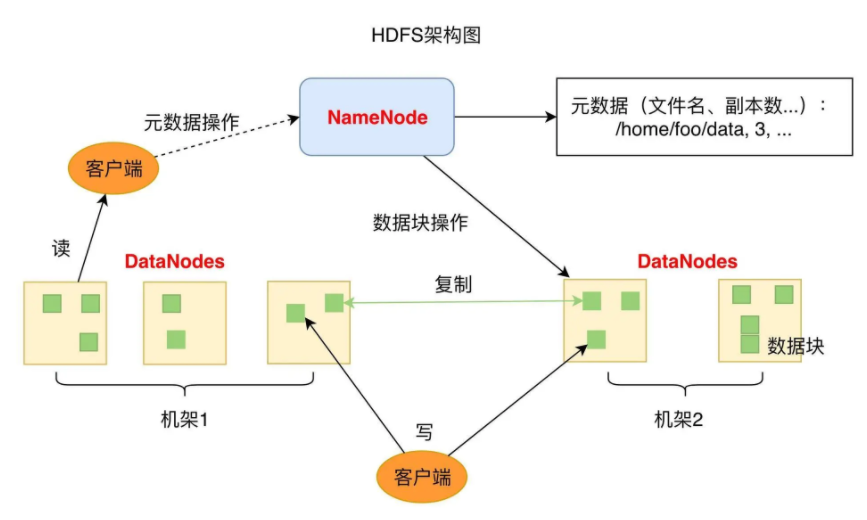
1 | 上图是HDFS的架构图,从图中你可以看到HDFS的关键组件有两个,一个是DataNode,一个是NameNode。 |
1 | 下面这张图是数据块多份复制存储的示意,图中对于文件/users/sameerp/data/part-0,其复制备份数设置为2,存储的BlockID分别为1、3。Block1的两个备份存储在DataNode0和DataNode2两个服务器上,Block3的两个备份存储DataNode4和DataNode6两个服务器上,上述任何一台服务器宕机后,每个数据块都至少还有一个备份存在,不会影响对文件/users/sameerp/data/part-0的访问。 |
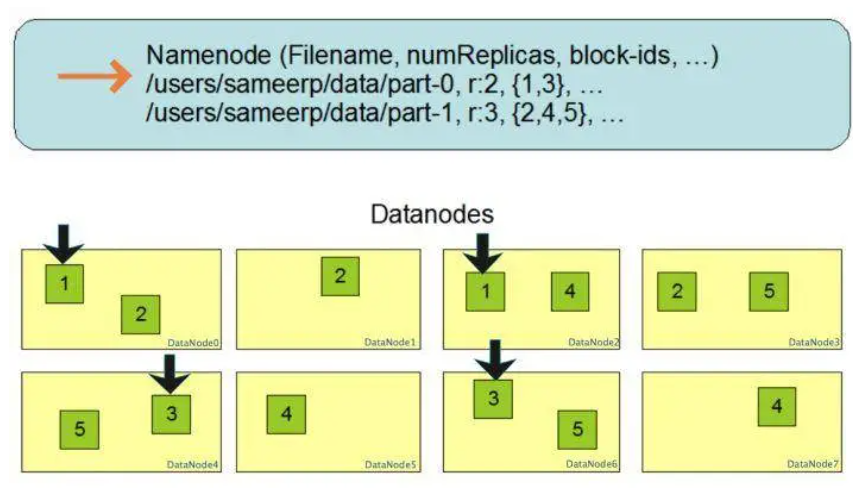
1 | 和RAID一样,数据分成若干数据块后存储到不同服务器上,可以实现数据大容量存储,并且不同分片的数据可以并行进行读/写操作,进而实现数据的高速访问。你可以看到,HDFS的大容量存储和高速访问相对比较容易实现 |
但是HDFS是如何保证存储的高可用性呢?
1 | 我们尝试从不同层面来讨论一下HDFS的高可用设计。 |
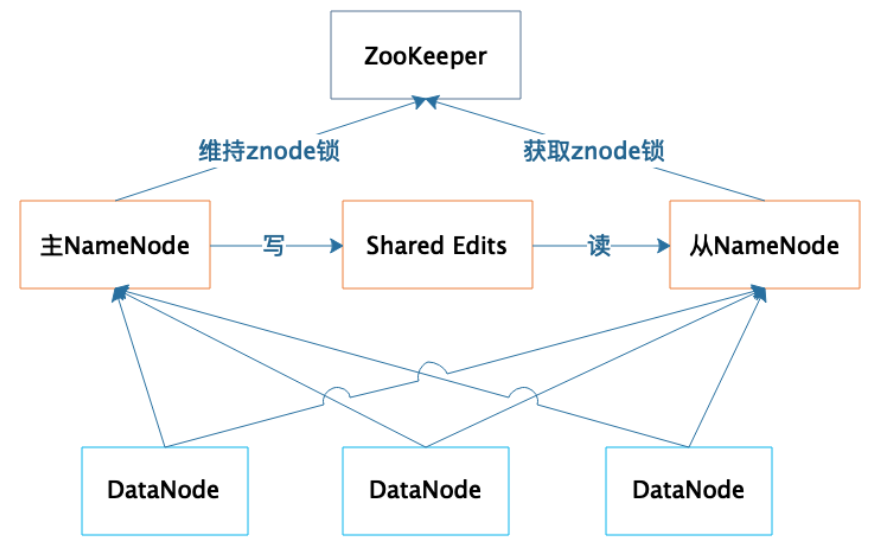
1 | 集群部署两台NameNode服务器,一台作为主服务器提供服务,一台作为从服务器进行热备,两台服务器通过ZooKeeper选举,主要是通过争夺znode锁资源,决定谁是主服务器。而DataNode则会向两个NameNode同时发送心跳数据,但是只有主NameNode才能向DataNode返回控制信息。 |
小结
我们小结一下,看看HDFS是如何通过大规模分布式服务器集群实现数据的大容量、高速、可靠存储、访问的。
1 | 1.文件数据以数据块的方式进行切分,数据块可以存储在集群任意DataNode服务器上,所以HDFS存储的文件可以非常大,一个文件理论上可以占据整个HDFS服务器集群上的所有磁盘,实现了大容量存储。 |

